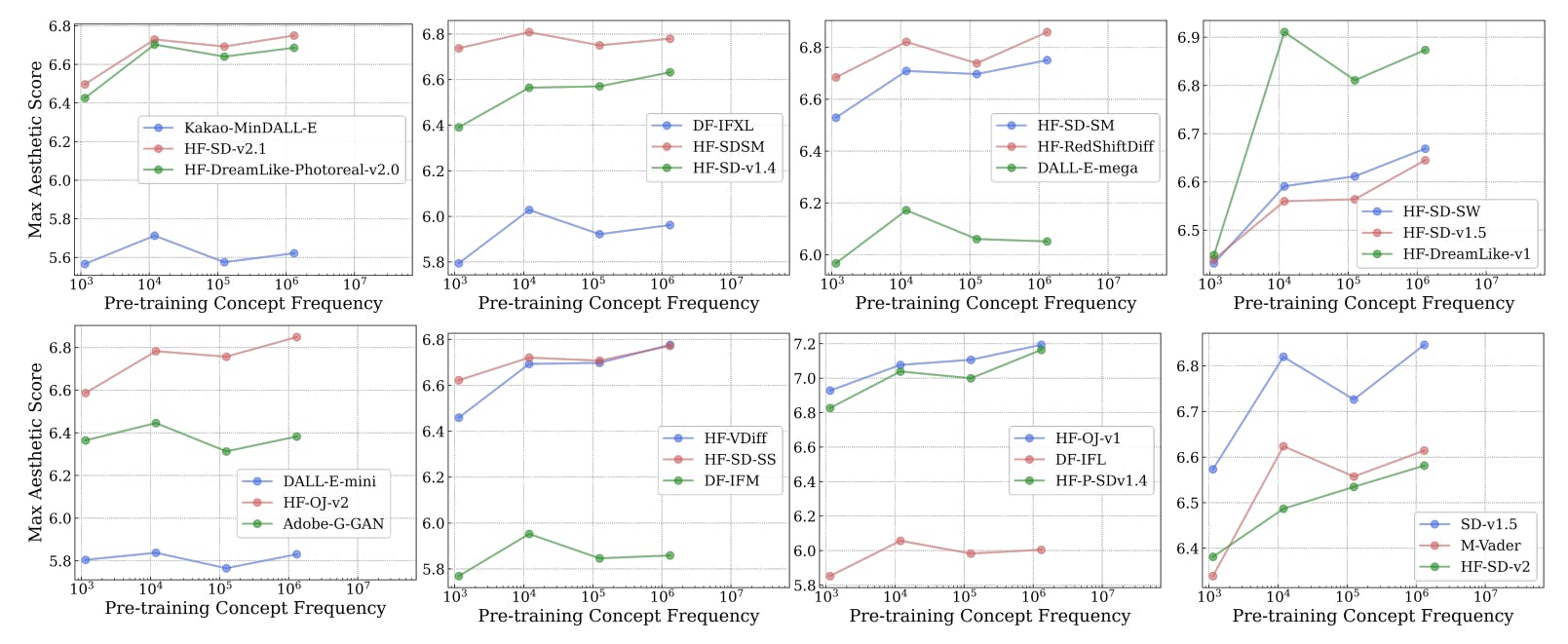
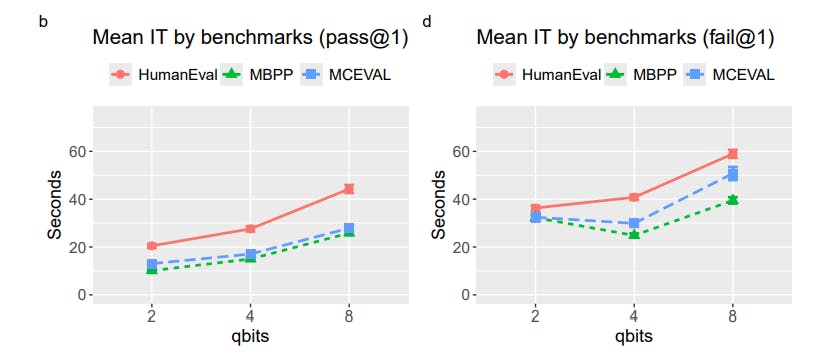
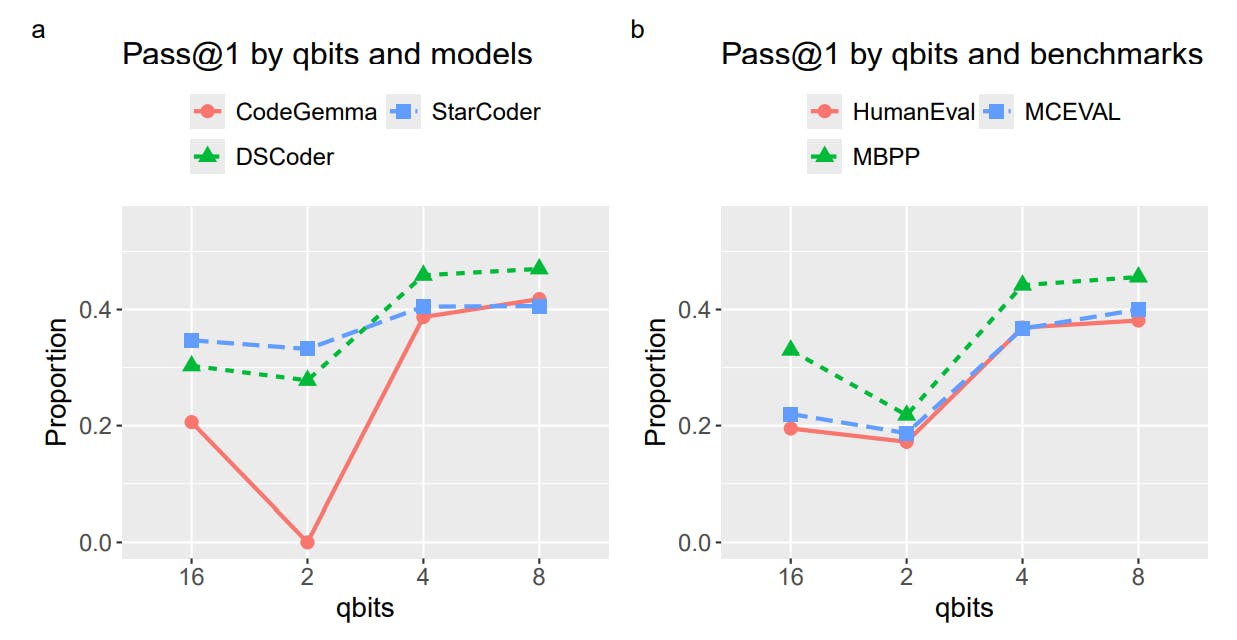
#model-performance
#model-performance
[ follow ]




fromBusiness Insider
3 months agoAI agents failed at real-world consulting tasks - but Mercor's CEO says they're still on track to replace consultants
New research suggests an AI agent can't fully replace a human consultant - at least for now. Mercor, the AI training giant, tested how well leading AI models, acting as agents, performed real-world consulting, banking, and legal tasks. The models failed most of the time, but Mercor's CEO, Brendan Foody, told Business Insider that the results tell only part of the story.
Artificial intelligence


fromEngadget
4 months agoChatGPT image generation is now faster and better at following tweaks
Following the release of GPT-5.2 last week, OpenAI has begun rolling out a new image generation model. The company says the updated ChatGPT Images is four times faster than its predecessor. If you're a frequent ChatGPT user, you'll know it can sometimes take a while for OpenAI's servers to create images, particularly during peak times and if you're not paying for ChatGPT Plus. In that respect, any improvement in speed is welcome.
Artificial intelligence
fromZDNET
5 months agoIs DeepSeek's new model the latest blow to proprietary AI?
Chinese AI firm DeepSeek has made yet another splash with the release of V3.2, the latest iteration in its V3 model series. Launched Monday, the model, which builds on an experimental V3.2 version announced in October, comes in two versions: "Thinking," and a more powerful "Speciale." DeepSeek said V3.2 pushes the capabilities of open-source AI even further. Like other DeepSeek models, it's a fraction of the cost of proprietary models, and the underlying weights can be accessed via Hugging Face.
Artificial intelligence
Artificial intelligence
fromMacRumors
5 months agoSam Altman Declares 'Code Red' for ChatGPT, Delays OpenAI Advertising Plans
OpenAI deprioritizes advertising to focus on improving ChatGPT's personalization, image generation, speed, reliability, and overall capability to remain competitive with Google and Anthropic.
fromInfoQ
8 months agoUnsloth Tutorials Aim to Make it Easier to Compare and Fine-tune LLMs
Qwen3-Coder-480B-A35B delivers SOTA advancements in agentic coding and code tasks, matching or outperforming Claude Sonnet-4, GPT-4.1, and Kimi K2. The 480B model achieves a 61.8% on Aider Polygot and supports a 256K token context, extendable to 1M tokens.
Artificial intelligence
Artificial intelligence
fromHackernoon
4 years agoMixture-of-Agents (MoA): Improving LLM Quality through Multi-Agent Collaboration | HackerNoon
The Mixture-of-Agents framework enhances large language model performance through collaboration among specialized models, achieving superior results without massive scaling.




[ Load more ]