"Pretraining data diversity plays a crucial role in affecting a model's performance, particularly in out-of-distribution generalization and systematicity."
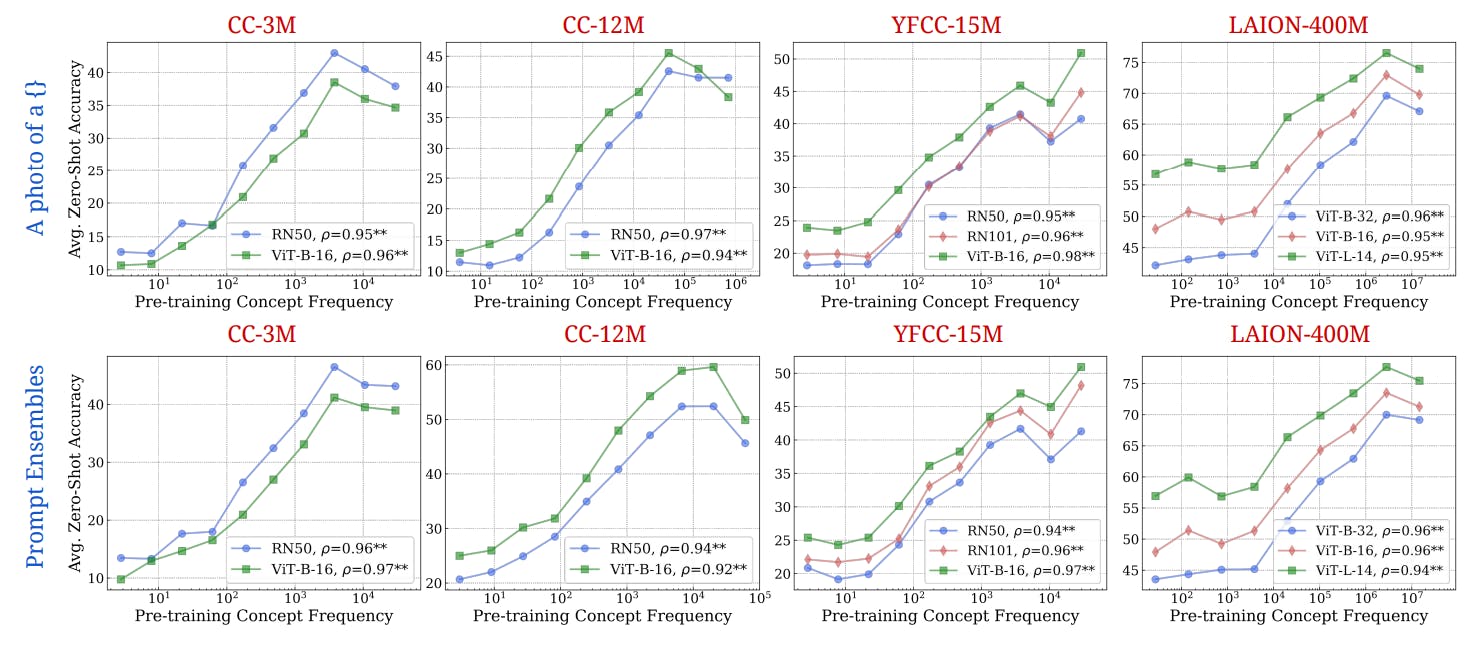
"Concept frequency during pretraining has predictive power over zero-shot performance, suggesting that more frequent concepts enhance model capabilities."
"Experimental results indicate that controlling for similar samples between pretraining and downstream data helps in assessing performance scaling trends."
"Models like CLIP exhibit strong generalization due to the diversity of pretraining data, illustrating important relationships between data characteristics and model behavior."
Pretraining data diversity is critical for the performance of models, impacting out-of-distribution generalization and effective data mixing strategies. Concept frequency during pretraining has shown to be predictive of zero-shot performance across various tasks. Experimental analyses involved controlling for sample similarities in pretraining and downstream data, revealing frequency-performance scaling trends. Insights suggest that attribute diversity is essential for compositional generalization, and different data distributions can lead to substantial performance variations, reinforcing the need for strategic pretraining data selection in model performance optimization.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]