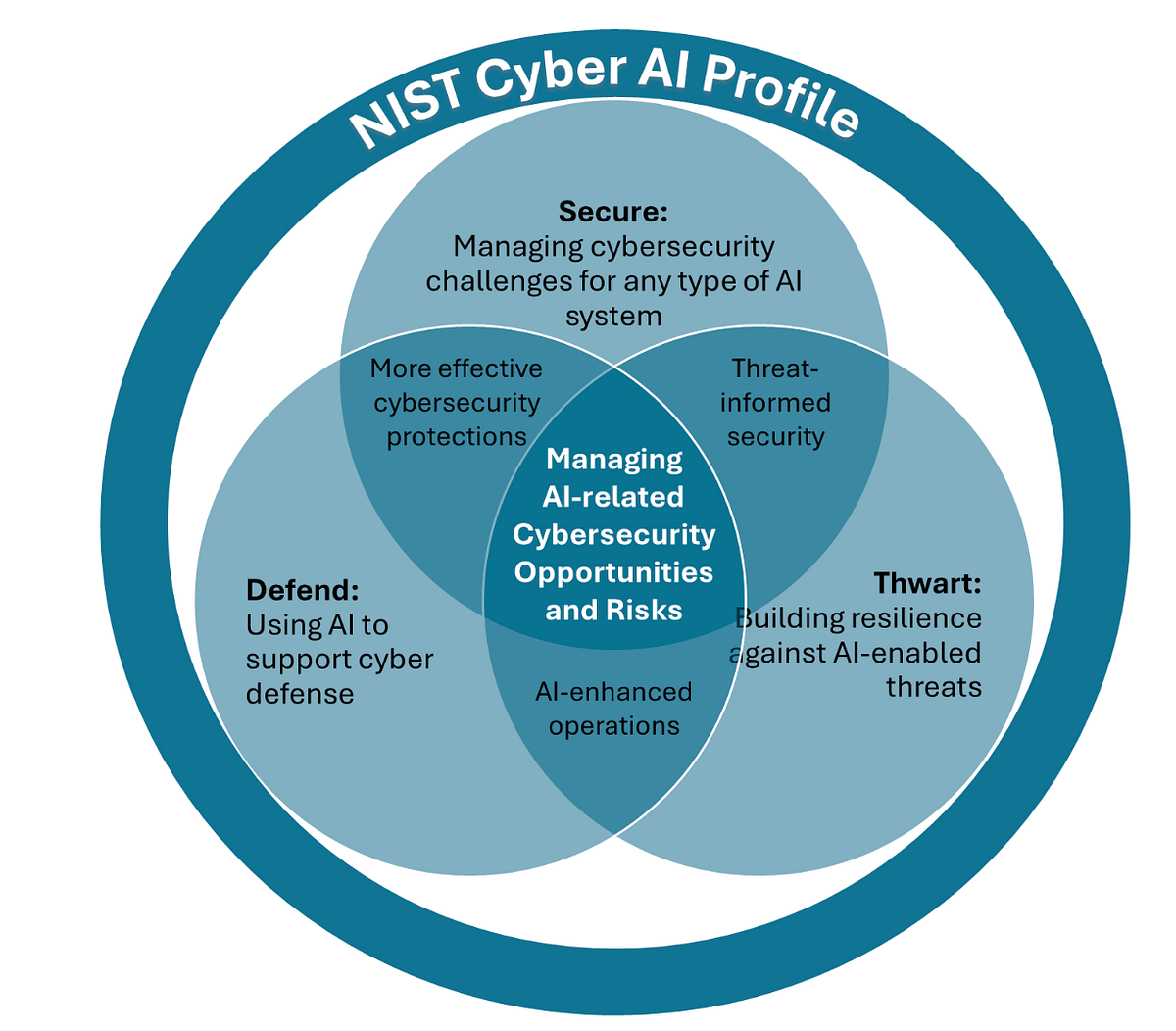
Information security
fromThe Hacker News
5 hours agoMost Remediation Programs Never Confirm the Fix Actually Worked
Patch faster, but verify fixes truly eliminate exposure rather than merely marking tickets remediated.
Tracebit has built cloud-native threat deception technology that uses tailored canaries to detect threats everywhere on a system. The canaries, which are described as fake honeypots, are deployed across the entire environment to attract threats and help organizations prevent cyberattacks and respond to incidents faster, employing an 'assume breach' approach.
Multiple repositories followed repeatable naming conventions and project 'family' patterns, enabling targeted searches for additional related repositories that were not directly referenced in observed telemetry but exhibited the same execution and staging behavior.
Web browsers are among the top targets for today's cybercriminals, playing a role in nearly half of all security incidents, new research reveals. According to Palo Alto Networks' 2026 Global Incident Response report, an analysis of 750 major cyber incidents recorded last year across 50 countries found that, in total, 48% of cybercrime events involved browser activity. Individuals trying to connect to the web, including business employees, are exposed to cyberthreats on a daily basis.
On February 3rd, we identified evidence of a problem with our systems that allowed an unauthorized third party to access limited user data without permission, including email addresses, phone numbers, and other internal metadata,
When your intern accidentally clicked on phishing link, don't panic. Take consistent but confident action. Even knowledgeable, tech-savvy people can click a fishing link. They may do this due to haste or the cunning design of a phishing message. Such events happen more often than you think. The consequences can vary. It may be an innocent redirect to a fake website, or downloading malicious software
Security in 2026 is defined by convergence, complexity, and scale. Enterprise organizations are navigating a world where cyber incidents are causing physical shutdowns, and physical breaches are creating digital vulnerabilities, all while cloud-dependent systems are becoming the backbone of operations, and AI is being used as a tool by both defenders and attackers. Incidents in 2025, especially the AWS outage, have painfully exposed just how interdependent modern security environments have become.
Microsoft first acknowledged the issues at 0900 UTC (although the status page for the service stated it spotted the problem at 0922 UTC). At the time, Microsoft blamed the Azure OpenAI Service's availability issues on "an unhealthy backend dependent service, which led to cascading failures." The Windows behemoth noted problems when using modes such as GPT-5.2, GPT-5 Mini, GPT-4.1, and related APIs.
Cloudflare recently published a detailed resilience initiative called Code Orange: Fail Small, outlining a comprehensive plan to prevent large-scale service disruptions after two major network outages in the past six weeks. The plan prioritizes controlled rollouts, improved failure-mode handling, and streamlined emergency procedures to make the company's global network more robust and less vulnerable to configuration errors. Cloudflare's network suffered significant outages on November 18 and December 5, 2025, with the first incident disrupting traffic delivery for about two hours and ten minutes
In organizations with mature processes, this demonstrably leads to a 30 to 50 percent reduction in mean time to respond. This is not an optimization, but a necessary adjustment. The question is no longer whether AI agents will be deployed, but how far their autonomy extends. Security teams must explicitly determine which decisions can be automated and where human oversight remains mandatory. If these frameworks are lacking, the risks only increase.
Manage My Health, a portal enabling connection between individuals and their healthcare providers, experienced a cyberattack identified on Dec. 30. The New Zealand-based organization published a statement to its website the following day, and as of Jan. 5, has continued to post subsequent updates as information has come available. Following the forensic investigations, the organization believes around 7% of 1.8 million registered patients may have been impacted.
Robust IT systems support uninterrupted operations through resilience, security, and proactive monitoring. CIOs report that 87% of digital-first businesses rely on automated failover systems to reduce service disruption. Continuous monitoring helps detect failures before they impact users. Recovery plans activate system redundancies and restore functions with minimal input. Automated backup schedules and patch management prevent gaps in continuity. IT managers emphasise the role of configuration management and centralised monitoring tools.