Social media marketing
fromwww.socialmediatoday.com
2 weeks agoInstagram brings simplified AI video to Edits
Instagram integrates AI tools for video generation from text prompts, enhancing user creativity without recording video.
Sora is currently only available on its website or as a standalone app, which has fallen shy of the popularity of ChatGPT. This update would allow users to access Sora's video generation capabilities directly within ChatGPT itself, much like the addition of image generation capabilities in the chatbot last year.
I imagined it would require technical skill-like some sort of advanced prompt engineering where I'd need to specify exactly how each file interacted with every other file. I thought I'd need to understand the "rules" of combining images with audio, or know the exact syntax for referencing multiple inputs. The reality was much simpler. Multi-modal input just means you can throw different types of files at Seedance 2.0 and tell the model
In a new viral AI video, Brad Pitt and Tom Cruise pummel each other on a rooftop in a cinematic action sequence. It's not a trailer for a new blockbuster, and it's not actually Pitt and Cruise, though it looks a lot like them. The video is so realistic, in fact, that the clearest sign it's made with AI is the dialogue.
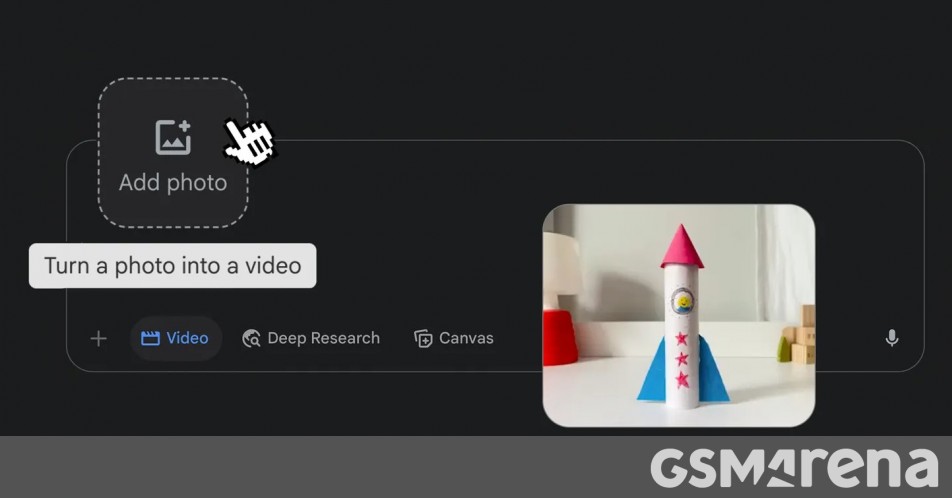
to the Photo to video feature in Google Photos. You now get "more creative control" to turn your images into "dynamic short videos". That's because you can now use text prompts for video generation, provided you are over 18. You can type a custom text prompt to describe the movement, style, or effect you want, and easily edit and refine your prompts to fine-tune the resulting video.
For example, OpenAI said in a blog post that the model was trained to be less overly optimistic, a characteristic that can be observed in instances where a Sora-generated video shows the player missing the shot but still making it into the hoop. With Sora 2, OpenAI claims the player would miss the shot, and the ball would rebound off the backboard.
Immutable backups prevent ransomware and ensure data integrity, meeting compliance needs with secure, tamper-proof cloud data protection. They safeguard critical data effectively.
Adobe's new Release of Generate Sound Effects (beta) allows users to create custom sounds by inserting a text description of what they'd like generated. Users can also use their voice to demonstrate the cadence or timing, enhancing control over sound generation.