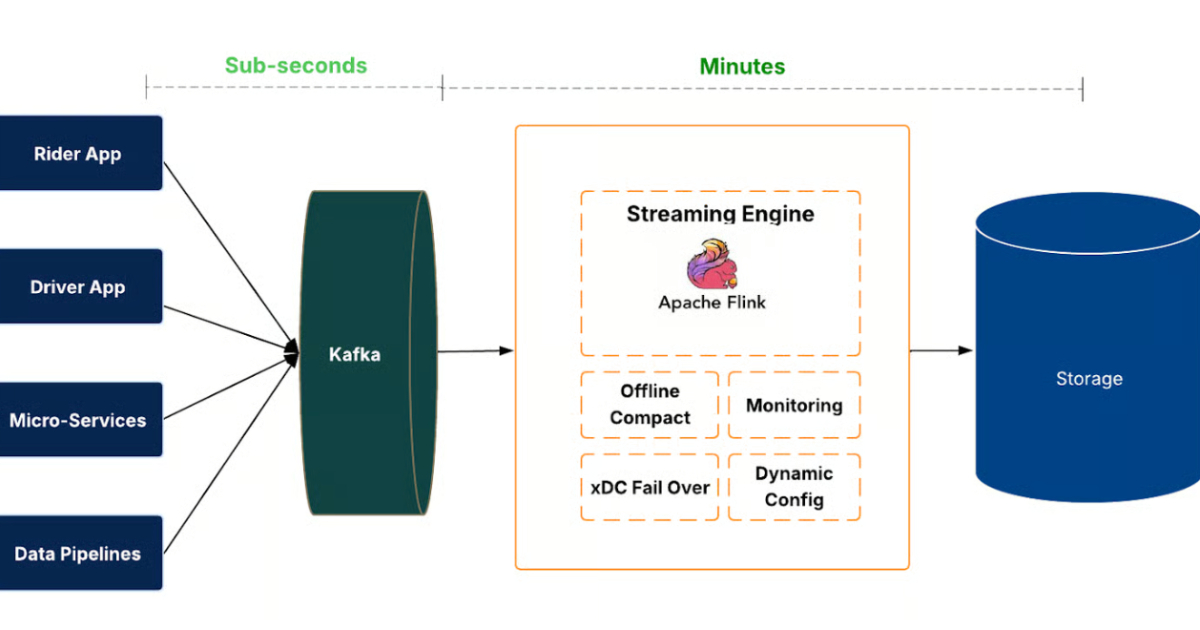
"This move is all about treating data freshness as a key dimension of data quality. IngestionNext introduces a streaming-first pipeline that continuously processes event streams before committing them to the data lake."
"The architecture supports thousands of datasets and high global data volumes, enabling faster availability for analytics dashboards, experimentation platforms, and machine learning models."
"Moving to a streaming ingestion model introduced several technical challenges, including creating many small files in the data lake, which can degrade query performance and storage efficiency."
Uber engineers have re-architected the data lake ingestion platform, IngestionNext, transitioning from scheduled batch jobs to a streaming-first system. This change reduces ingestion latency from hours to minutes, enhancing data availability for analytics and machine learning. The platform processes event streams continuously using Apache Kafka and Flink jobs, ensuring data freshness and completeness. It supports high data volumes and thousands of datasets, while also implementing strategies to manage file efficiency and prevent data loss during outages.
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]