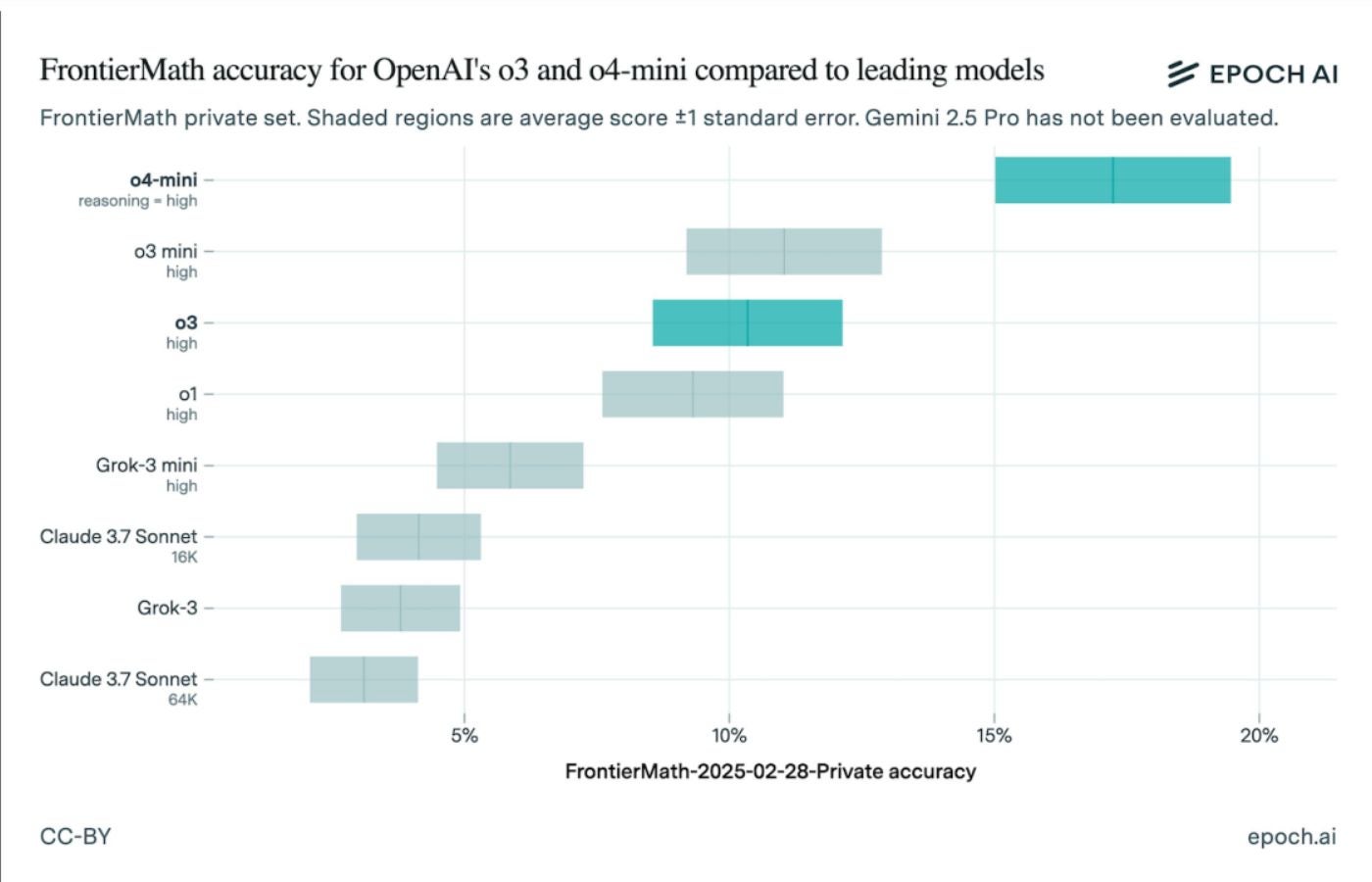
"Epoch AI's latest results reveal that OpenAI's o3 model only completed about 10% of the FrontierMath test, contrasting sharply with earlier claims of 25% completion."
"The evaluation of generative AI performance on benchmarks unveils discrepancies that suggest any representation of AI capabilities must be critically analyzed and understood."
"OpenAI's newer models now outperform o3, but the variances in earlier claims emphasize the importance of closely scrutinizing AI benchmarks and their methodologies."
"Epoch AI, while independently administering FrontierMath, reflects on the broader implications of benchmark data, urging users to consider version changes when interpreting performance results."
The recent FrontierMath benchmark tests suggest that OpenAI's o3 model performed significantly worse than previously stated. Originally claimed to have solved over 25% of problems, actual performance was only about 10%. This discrepancy arose partly due to differences in model versions and test content from last December. OpenAI's newer models, o4 and o3 mini, showed improved results, but the findings emphasize the critical need to scrutinize AI benchmarking practices, including understanding changes in model variations and performance metrics over time.
Read at TechRepublic
Unable to calculate read time
Collection
[
|
...
]