This article discusses the emergence of Multi-Token Attention (MTA) as a significant advancement in transformer architecture for natural language processing. Unlike traditional single-token attention, which evaluates each token in isolation, MTA allows models to consider multiple tokens together, enhancing contextual understanding in language tasks. The article outlines the mechanics of standard attention and explains the limitations it presents, particularly the inability to recognize simultaneous patterns across tokens. By employing MTA, transformers can improve their performance in various applications, including language models, vision transformers, and multi-modal architectures with balanced benefits and trade-offs.
"Transformers' traditional attention focuses on individual tokens; however, Multi-Token Attention (MTA) allows for simultaneous consideration of token groups, enhancing model capabilities."
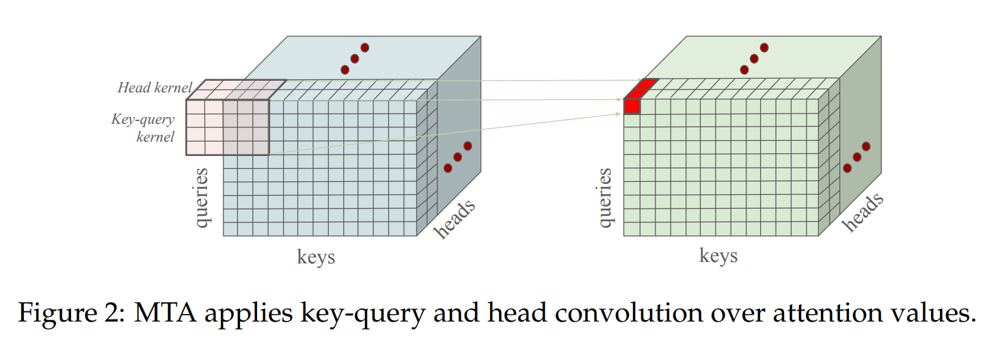
"With standard attention, each token processes information in isolation, making it difficult to capture interactions across multiple tokens. MTA addresses this by examining groups of tokens simultaneously."
"The multi-head attention mechanism provides diverse perspectives on sequences, but it remains limited by processing single tokens independently. MTA enriches contextual representation by leveraging groups."
"Exploring Multi-Token Attention reveals potential benefits and trade-offs for various architectures, highlighting a significant shift in how models can evaluate contextual relevance."
#transformers #natural-language-processing #multi-token-attention #attention-mechanisms #machine-learning
Read at Medium
Unable to calculate read time
Collection
[
|
...
]