Transformers have transformed natural language processing with their attention mechanisms that highlight relevant tokens. Yet, traditional attention analyzes only one token at a time, leaving gaps in contextual understanding. Multi-Token Attention (MTA) emerges as a solution, allowing simultaneous attention to multiple tokens, which improves the model's ability to capture complex relationships. The article discusses how MTA operates, its necessity compared to standard attention, and the trade-offs it presents for enhancing the capabilities of language models, vision transformers, and multi-modal architectures.
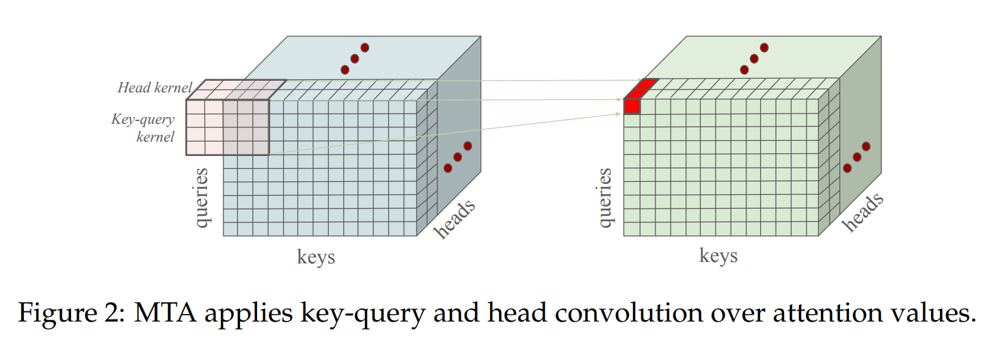
"Multi-Token Attention (MTA) allows transformers to process and attend to groups of tokens simultaneously, enhancing the model's contextual understanding and performance."
"Existing single-token attention considers one token at a time, whereas MTA enables models to simultaneously evaluate multiple tokens, providing greater flexibility and a more nuanced understanding."
"MTA introduces significant benefits for tasks that involve complex relationships among multiple tokens, improving performance in language models, vision transformers, and multi-modal architectures."
"While MTA enhances attention capabilities, it also introduces trade-offs that need to be understood in relation to model complexity and computational efficiency."
#transformers #natural-language-processing #attention-mechanisms #multi-token-attention #machine-learning
Read at Medium
Unable to calculate read time
Collection
[
|
...
]