fromwww.scientificamerican.com
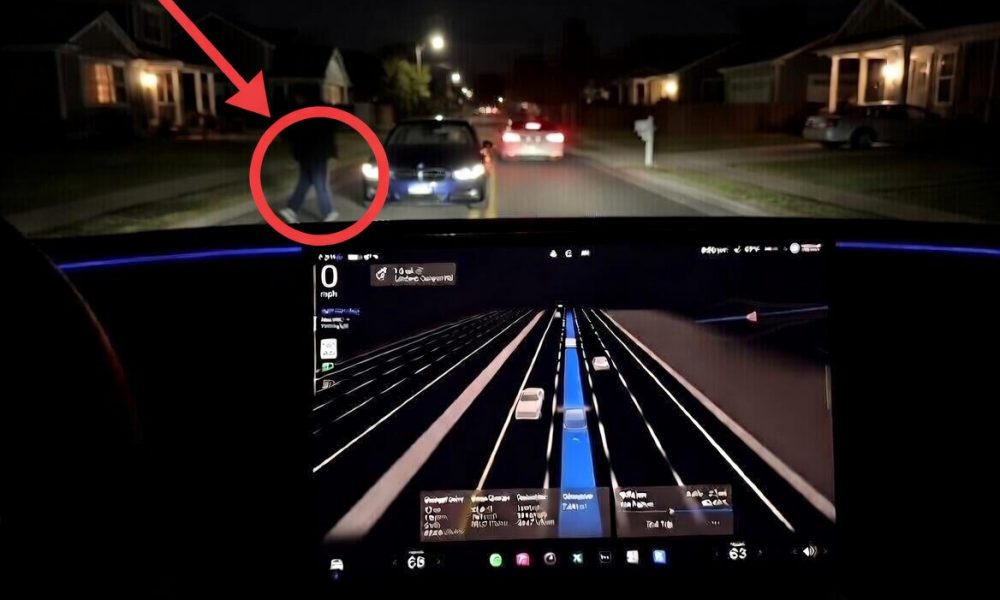
3 hours agoTiny robot drones learn to navigate the world like honeybees
A honeybee leaving the hive first takes a short learning flight to memorize nearby landmarks. As a bee flies away, it keeps track of the direction and speed of its movement, de Croon says, in a process called path integration. Because path integration is prone to accumulating tiny measurement errors over time, the insect relies on the memorized landmarks to correct its course as it gets back home.
Roam Research
.jpg)