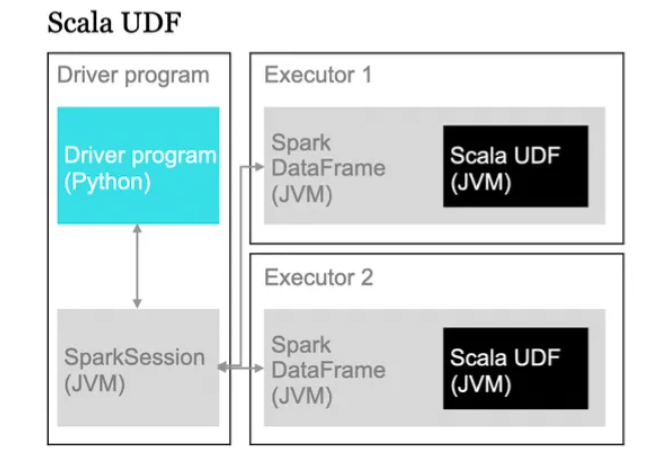
"User Defined Functions (UDFs) in Spark Scala allow developers to implement custom business logic beyond built-in functions for tailored data processing."
"UDFs must be designed with null safety in mind, leveraging techniques like Option to avoid runtime errors and enhance robustness in data pipelines."
"Testing UDF logic separately and avoiding their use inside joins or wide aggregations is essential for maintaining performance and optimizing execution plans in Spark."
"Utilizing UDFs not only enhances flexibility in expressing complex business rules but also transforms Spark into a powerful tool for generating insights and custom APIs."
The article introduces User Defined Functions (UDFs) in Spark Scala, highlighting their importance for implementing specific business logic that cannot be addressed by built-in functions. It emphasizes the need for null safety in UDFs using structures like Option to prevent runtime errors. Additionally, the article outlines best practices for UDF implementation, including unit testing and avoiding UDFs in joins or wide aggregations for performance reasons. It concludes by showcasing how mastering UDFs can elevate Spark's functionality, turning it into a robust engine for applying complex business rules and generating insightful outputs.
Read at medium.com
Unable to calculate read time
Collection
[
|
...
]