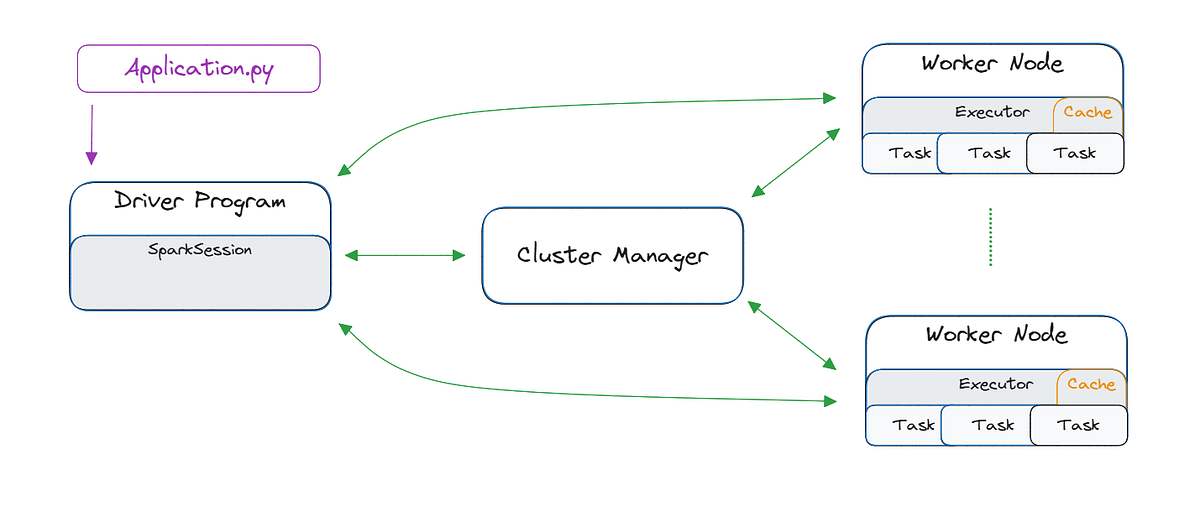
"Apache Spark integrates seamlessly into the Big Data ecosystem, simplifying data processing through its robust architecture which includes a Driver Program, Cluster Manager, and Worker Nodes."
"Understanding the 5 V's of Big DataâVolume, Velocity, Variety, Veracity, and Valueâprovides insight into how necessary robust systems must be to tackle modern data challenges."
This article introduces Apache Spark by situating it within the Big Data ecosystem, focusing on its core components and architectural features. It outlines the 5 V's of Big DataâVolume, Velocity, Variety, Veracity, and Valueâhighlighting the essential properties of a successful Big Data system. Apache Spark addresses common challenges in Big Data through its Driver Program, Cluster Manager, and Worker Nodes, streamlining data processing tasks. By the end of the article, readers will gain confidence in using Spark for their Big Data projects.
Read at Medium
Unable to calculate read time
Collection
[
|
...
]