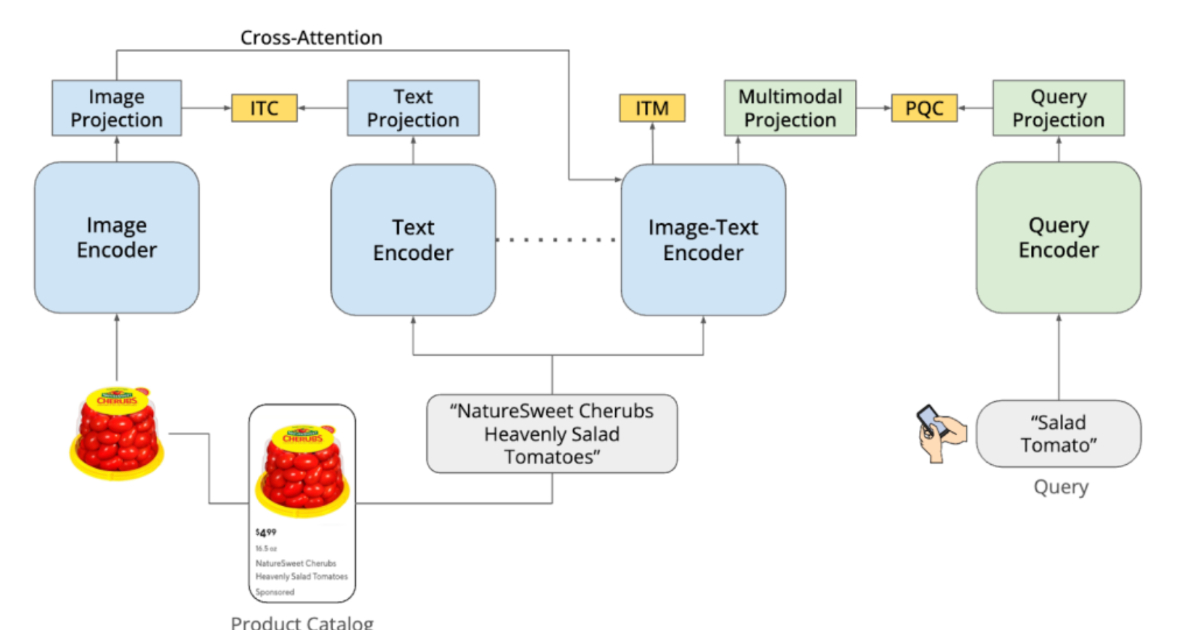
"DashCLIP is a multimodal machine learning system designed to generate semantic embeddings by aligning product images, text descriptions, and user queries in a shared representation space. The architecture aims to improve product discovery, ranking, and advertising relevance across the company's Consumer Packaged Goods (CPG) marketplace."
"DoorDash's marketplace spans diverse categories, including groceries, retail goods, electronics, and pharmaceuticals. This variety challenges traditional search and recommendation systems that rely on structured metadata and historical engagement signals. These approaches often miss semantic relationships between product images, descriptions, and user intent."
"DashCLIP builds on contrastive learning approaches, such as CLIP. It uses separate encoders for product images, text descriptions, and user queries, each producing vector embeddings. During training, semantically related items are placed close together in the embedding space while unrelated items are pushed apart."
DashCLIP is a multimodal machine learning system that generates semantic embeddings by aligning product images, text descriptions, and user queries in a shared representation space. Trained on approximately 32 million labeled query-product pairs, the system addresses challenges in DoorDash's diverse marketplace spanning groceries, retail, electronics, and pharmaceuticals. Traditional search systems struggle with semantic relationships between visual and textual information. DashCLIP uses separate encoders for images, text, and queries, applying contrastive learning to place semantically related items close together in embedding space while pushing unrelated items apart. This architecture enables effective product matching even with incomplete descriptions or when visual attributes are critical to user intent.
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]