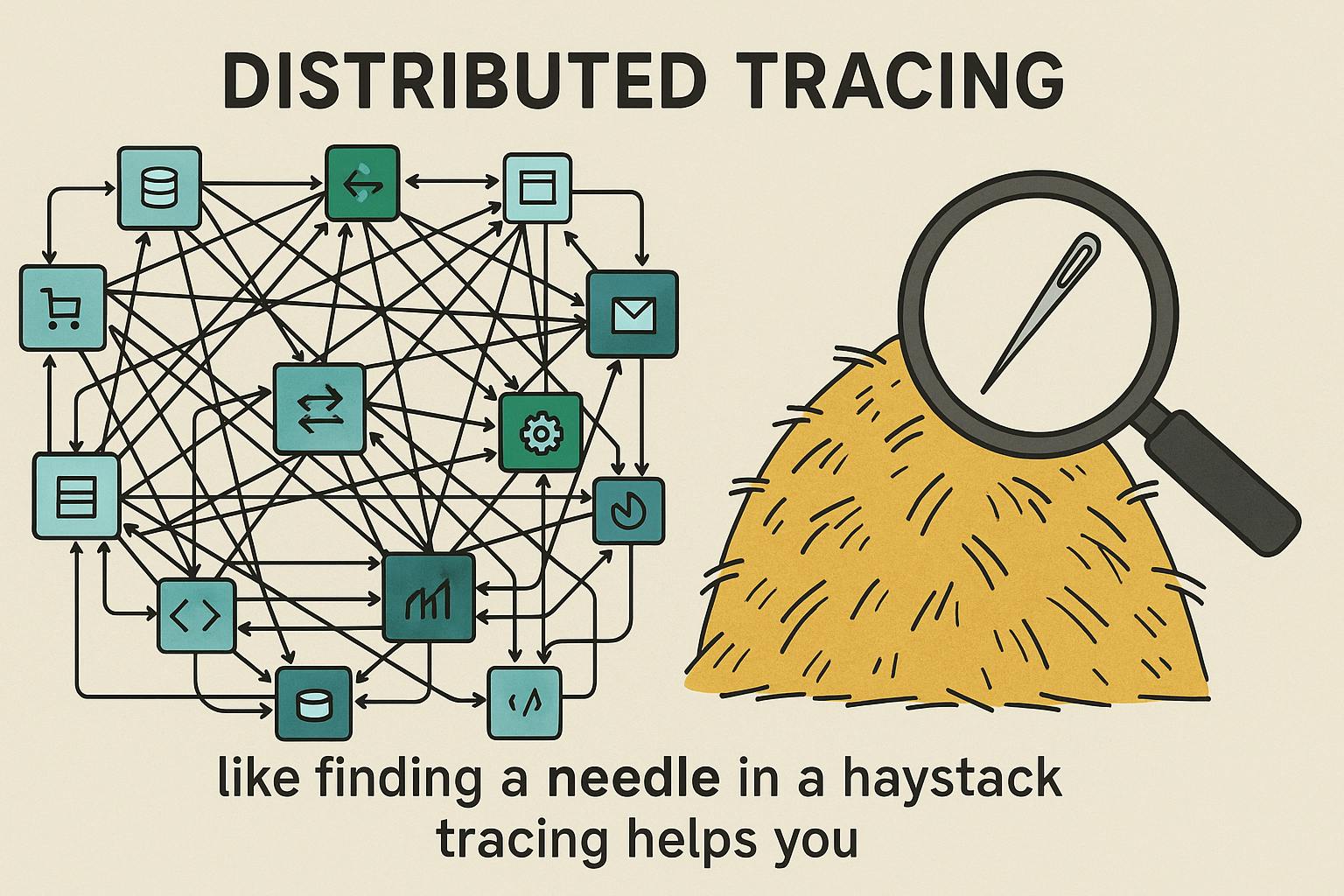
"Without distributed tracing, you're reduced to checking individual service metrics, digging through log lines across multiple services, and hoping someone remembers the architecture."
"With distributed tracing, you can see the entire request flow and pinpoint exact database queries or code blocks causing the problem."
"Metrics tell you something's wrong. Logs might tell you what's wrong. Traces tell you why and where it's wrong."
"Distributed systems have become the norm, and with that transition comes a new class of observability challenges."
The article emphasizes the importance of distributed tracing in managing microservices architectures. It highlights the challenges faced without tracing, such as manual logging and inefficient problem-solving during outages. With distributed tracing, teams can visualize request flows, identify latency issues, and deploy fixes rapidly. The piece also introduces the three pillars of observability: logs, metrics, and traces, explaining their interrelations and individual value in troubleshooting. Experts like Ben Sigelman and Charity Majors underline the shift to distributed systems and the need for robust observability frameworks to navigate these complexities.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]