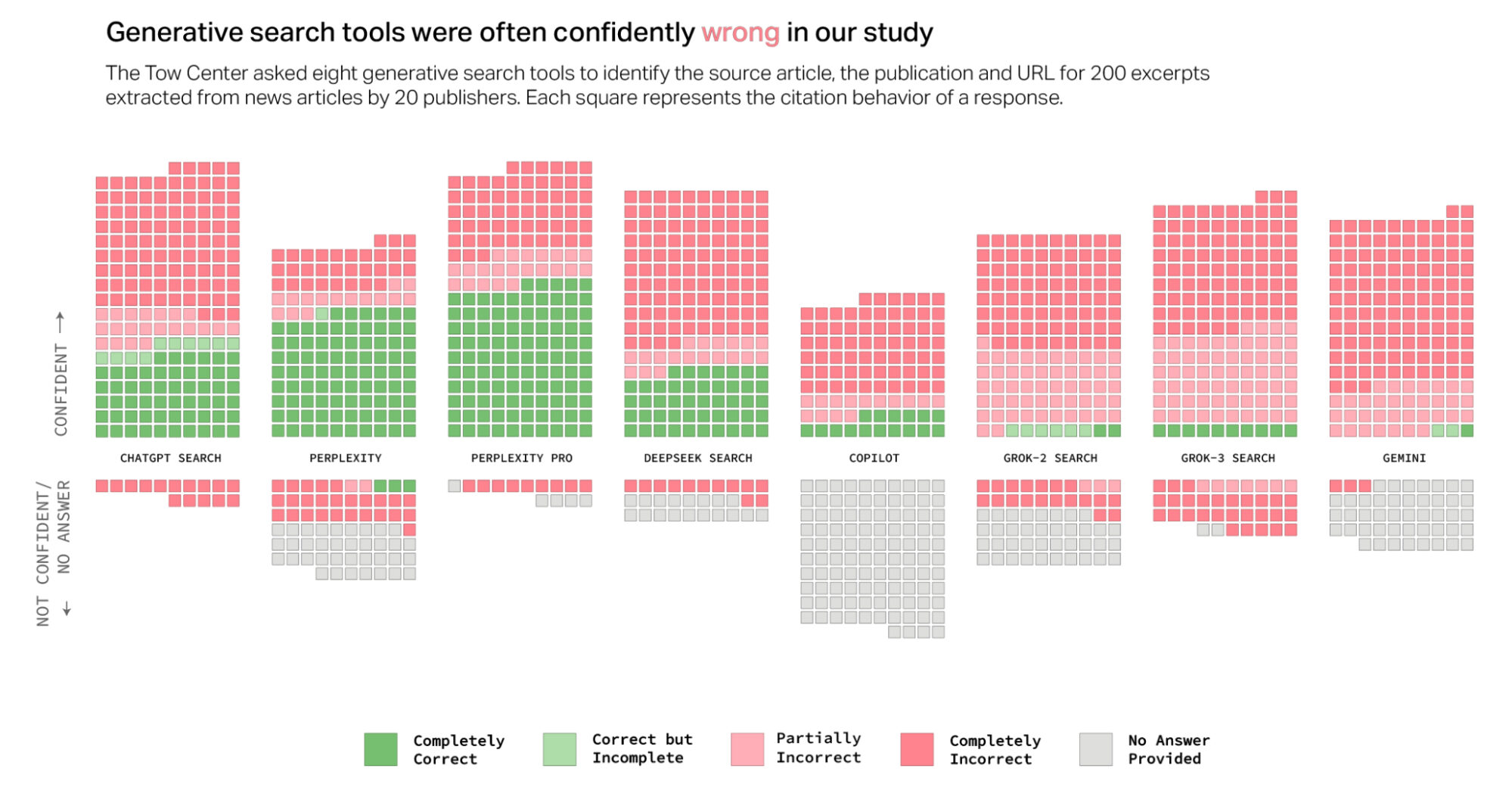
""Overall, the chatbots often failed to retrieve the correct articles. Collectively, they provided incorrect answers to more than 60 percent of queries.""
""Across different platforms, the level of inaccuracy varied, with Perplexity answering 37 percent of the queries incorrectly, while Grok 3 had a much higher error rate, answering 94 percent of the queries incorrectly.""
In a test conducted by Klaudia JaźwiÅska and Aisvarya Chandrasekar for Columbia Journalism Review, several AI chatbots were evaluated for accuracy in citing articles. The results were concerningâchatbots collectively failed to provide correct answers over 60% of the time. The accuracy varied significantly among them, with Perplexity inaccurately answering 37% of queries, while Grok 3's error rate soared to 94%. This raises important questions about the reliability of AI-generated information and the necessity for users to develop skills in discernment.
Read at FlowingData
Unable to calculate read time
Collection
[
|
...
]