"The long-tailed concept distribution indicates that models may significantly underperform when faced with data distributions that have rare concepts, testing the limits of their generalization."
"The 'Let It Wag!' dataset consists of 130K test samples extracted from the web, specifically designed to evaluate performance on infrequent concepts and ensure balanced representation."
"Identifying the least frequent concepts in pretraining allows for the assessment of how well models can generalize and perform under conditions of concept scarcity."
"Results indicate that pretraining frequency plays a significant role in predicting 'zero-shot' performance, particularly when models are exposed to rare concepts."
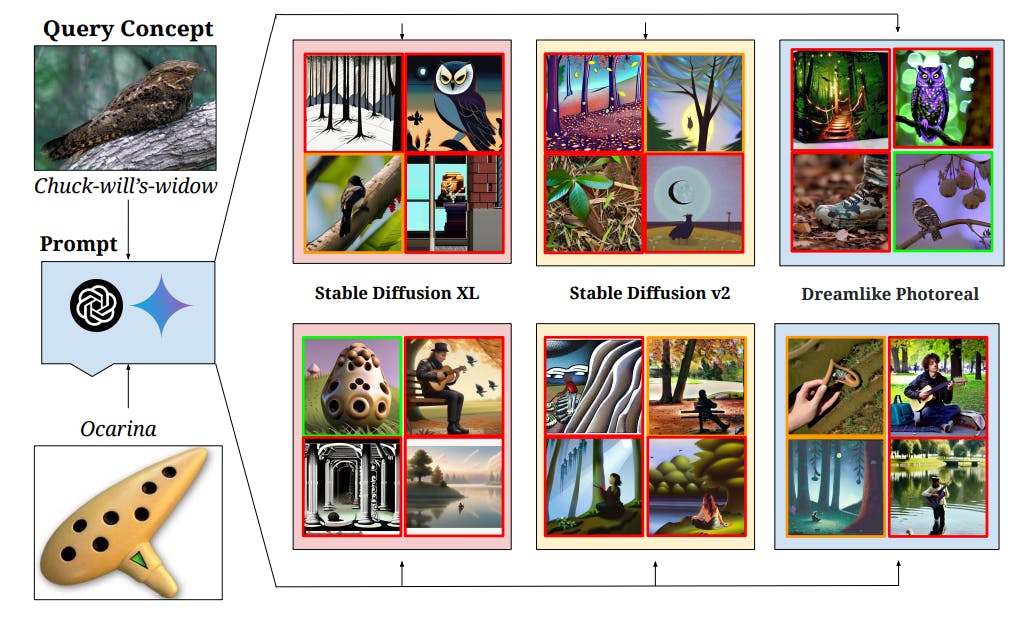
The study identifies a long-tailed distribution of concept frequencies within pretraining data. It hypothesizes that models trained on these data distributions will struggle with rarity of concepts. A dataset called 'Let It Wag!' was created, consisting of 130K test samples from the web, focusing on the least frequent concepts. This dataset allows for a classification test aimed at evaluating model performance on underrepresented concepts. The results show that pretraining concept frequency is a key predictor of performance in zero-shot settings, highlighting challenges in generalization when rare concepts are encountered.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]