"We define 'concepts' as the specific objects or class categories we seek to analyze in the pretraining datasets, such as the 1,000 classes in ImageNet."
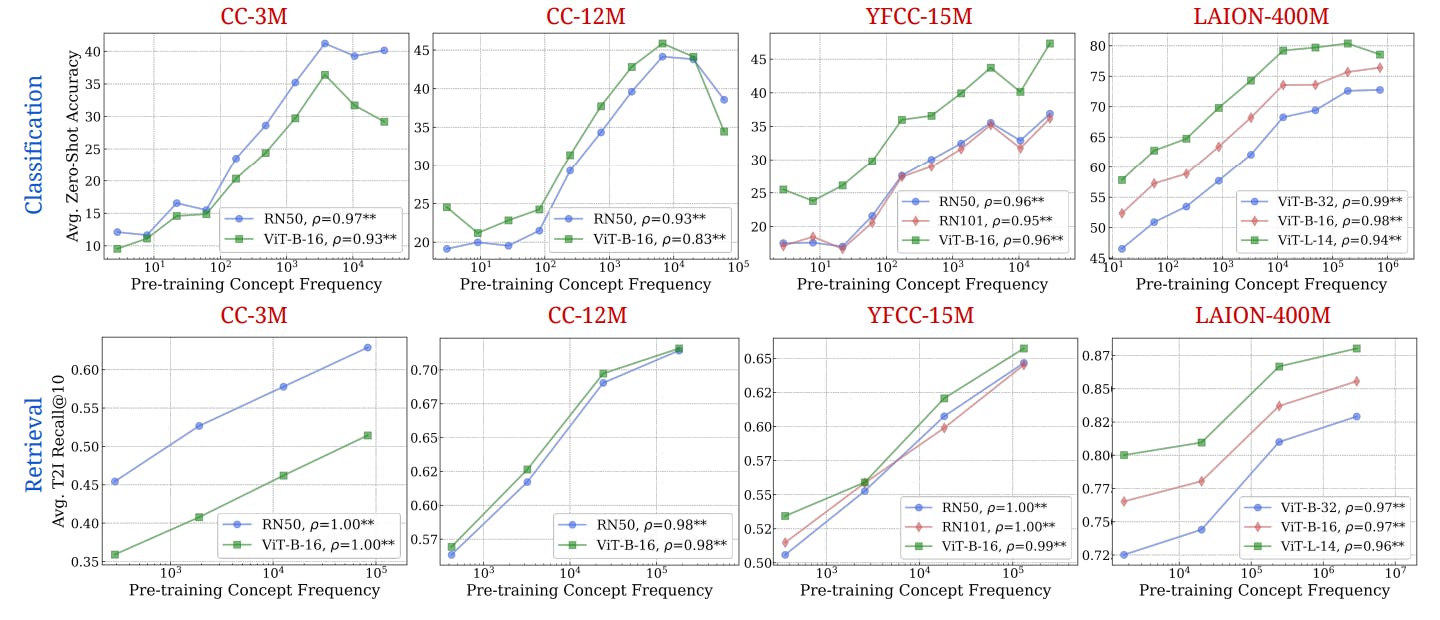
"The experimental setup tests the prediction that pretraining frequency is predictive of ‘zero-shot’ performance across different models and tasks."
"Concept frequency is shown to have a significant impact on performance not only for direct image and text applications but also extending to synthetic data scenarios."
"Results reveal that controlling for similar samples in pretraining and downstream data is crucial in validating the frequency-performance scaling trend."
Concepts are defined as specific objects or class categories within pretraining datasets. This methodology involves extracting frequencies of these concepts from images and text captions. The analysis includes matched image-text concept frequencies. The experiments confirm that pretraining frequency correlates positively with ‘zero-shot’ performance across various tasks. Further testing explores how concept frequencies affect performance with synthetic data distributions and emphasizes the importance of controlling for sample similarities. Significant trends reveal that frequency-performance relationships are critical for understanding model generalization.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]