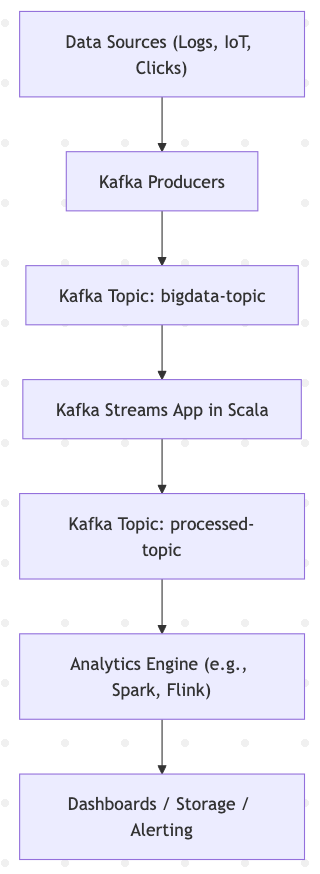
"Modern data systems demand scale, speed, and reliability, which Kafka provides as a high-throughput streaming backbone, paired effectively with Scala’s capabilities."
"Scala ensures safer concurrent stream processing through immutability and thread safety, making it suitable for deploying in distributed, parallel environments with Kafka."
"Using Kafka with Scala allows for handling millions of logs per second using efficient architectures, providing reduced latency in anomaly detection and analysis."
"Implementing best practices like batching, backpressure management, and effective serialization aids in optimizing Kafka’s data processing capabilities in big data pipelines."
Combining Kafka with Scala provides a powerful framework for building real-time, scalable big data pipelines. Scala's features such as immutability and thread safety enhance concurrent stream processing. Kafka serves as a robust backbone for high-throughput streaming, suited for applications like IoT systems and financial transaction monitoring. Techniques such as partitioning, serialization improvements, and backpressure management are crucial for optimizing performance in large-scale systems, allowing for efficient data handling and reduced latency in various use cases like anomaly detection and traffic analysis.
Read at medium.com
Unable to calculate read time
Collection
[
|
...
]