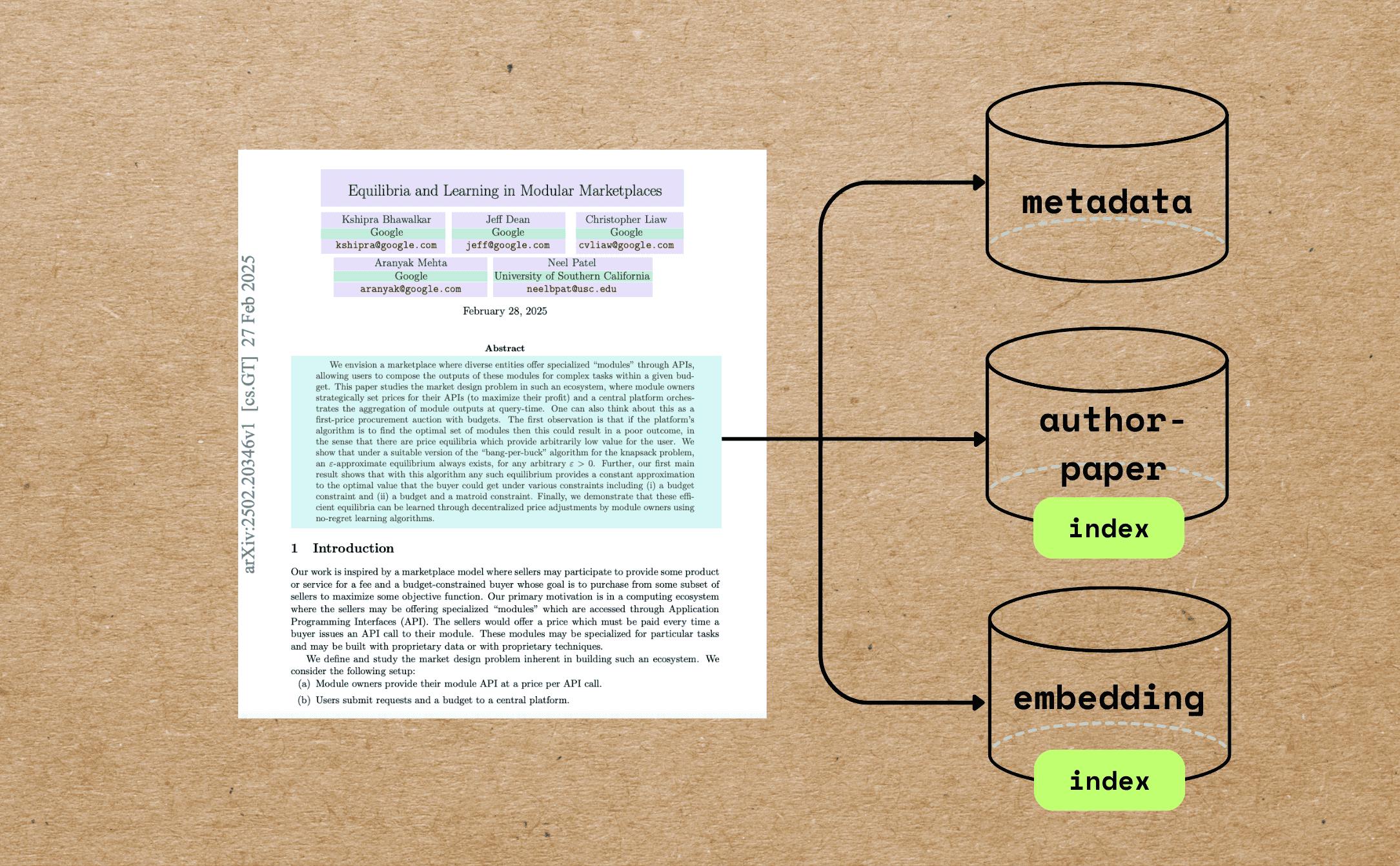
The article outlines a method for indexing research papers that involves extracting various metadata elements, such as title, author info, and abstract. By creating vector embeddings for this metadata, academic search capabilities are improved, allowing for precise semantic search and query matching. It details processes such as PDF preprocessing to gather initial data, converting to Markdown, and leveraging LLMs for metadata extraction. Semantic embeddings are created for titles and abstracts to further enhance search functionality, along with author indexing for easy access to specific papers.
"Extracting metadata from research papers facilitates better academic search and retrieval dynamics. By building semantic embeddings for metadata, users gain enhanced search capabilities that match user queries with relevant content."
"By indexing author information along with their associated paper file names, users can quickly retrieve relevant works, such as querying for all papers authored by a specific individual. This enriching of metadata aids in research efficiency."
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]