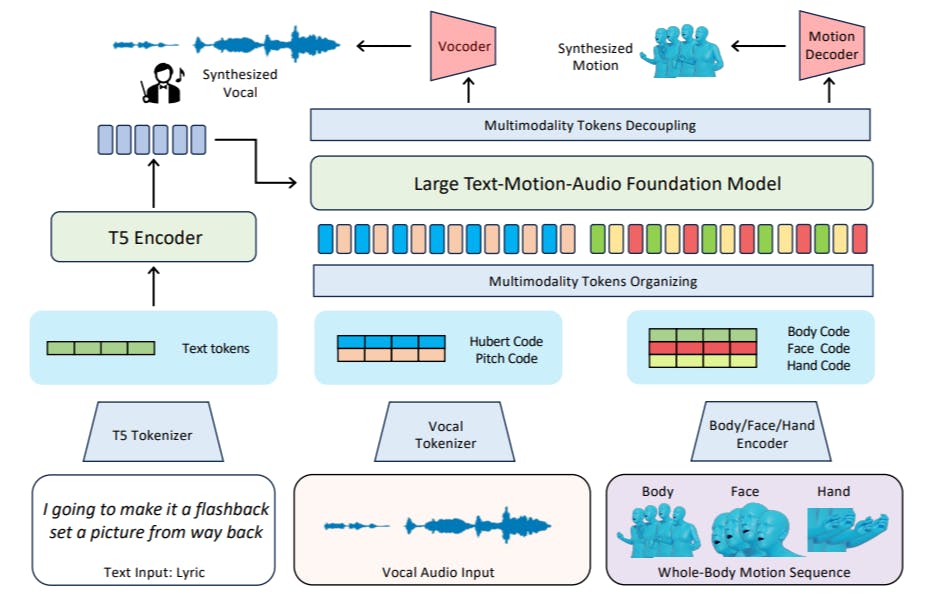
"The proposed framework integrates token modeling for rap-style vocals and motions, representing texts, vocals, and motions as unified token forms."
"Our Vocal2unit audio tokenizer learns vocal representations from audio sequences, utilizing three encoders to build a discrete tokenized representation for singing."
"The model's training objective involves predicting the next token, allowing decoding into various modality features, similar to text generation in language models."
"In inference, start tokens specify the modality to generate, with textual input encoded to guide token inference and control content diversity."
A framework generates rap-style vocals and body motions from lyrics by integrating token modeling for texts, vocals, and motions. The model includes multiple tokenizers such as the Motion VQ-VAE Tokenizer and Vocal2unit Audio Tokenizer, which create discrete representations of motion and vocal elements. The training involves using self-supervised techniques to optimize vocal encodings. Additionally, inference utilizes specified start tokens to produce content across modalities, guided by encoded text, while controlling generation diversity through a top-k algorithm.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]