"The feed forward layer in transformer models is crucial for reasoning on token relationships, often housing most of the model's weights due to its larger dimensionality."
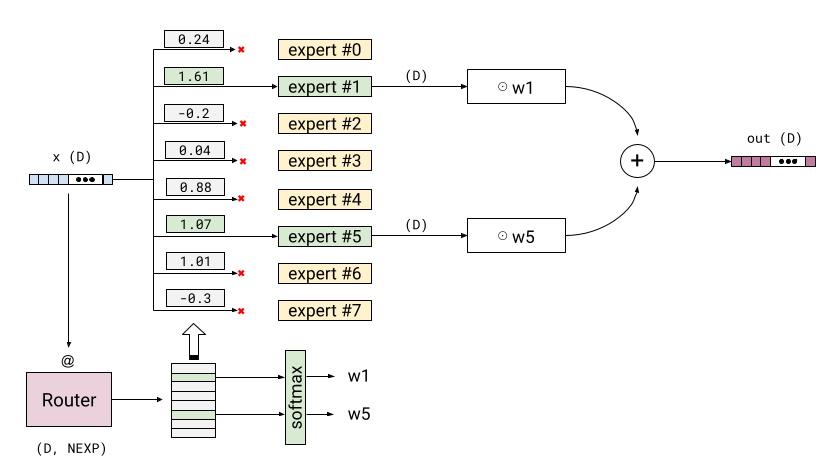
"The Mixture of Experts (MoE) architecture enhances efficiency by splitting the large feed forward layer into several experts, allowing selective processing for each input."
"In MoE, a router layer assesses each token's relationship with multiple experts, dynamically selecting the best ones to streamline computation while maintaining accuracy."
"By utilizing only the highest scoring experts from the Mixture of Experts approach, transformers significantly reduce computational load, improving efficiency during training and inference."
In transformer models, the feed-forward layer follows the attention block and is essential for complex reasoning on token embeddings. Typically, this layer is larger than the others, as it is designed to perform the majority of the heavy lifting in terms of processing. To enhance efficiency, the Mixture of Experts (MoE) architecture has emerged, splitting the large feed-forward layer into multiple "expert" blocks, with a router selecting the best-performing experts for specific tokens, leading to a more efficient model overall by utilizing a reduced computational load.
Read at Thegreenplace
Unable to calculate read time
Collection
[
|
...
]