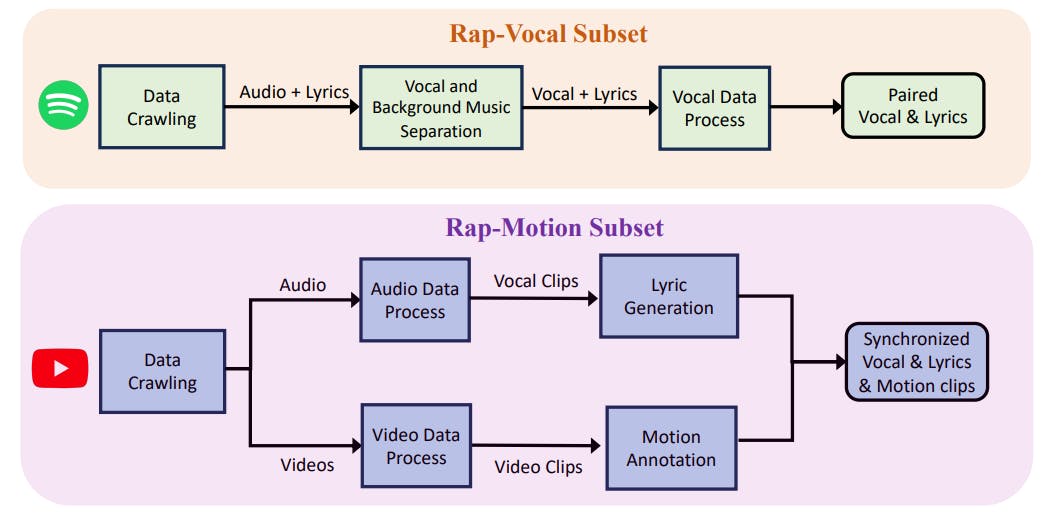
"The dataset represents the first specifically curated for rap songs, including 108 hours of recordings covering multiple singers, significantly enriching the available resources."
"Current TTS models, such as WavNet and FastSpeech, improve synthesized speech quality but face challenges in singing voice synthesis due to musical score dependencies."
"StyleSinger incorporates a Residual Style Adaptor and an Uncertainty Modeling Layer Normalization to manage performance issues with out-of-distribution data in singing voice synthesis."
"Motion-X was developed as a comprehensive text-to-motion dataset, overcoming existing limitations with whole-body motion representation and expanding data coverage."
A new dataset has been introduced that focuses on rap songs and includes 108 hours of recordings from multiple singers. Existing singing vocal datasets have limitations in language or duration. Text-to-speech models have advanced, yet challenges remain in singing voice synthesis due to the need for musical scores. Recent models like StyleSinger have improved capabilities to handle out-of-distribution data. Additionally, text-to-motion datasets have traditionally suffered from limited data, prompting the creation of Motion-X to provide more extensive whole-body motion representations.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]