"To enhance the understanding of the proposed system's generation quality, a supplemental website demo displays additional qualitative results, emphasizing vivid and clear outputs."
"Three separate Vector Quantized Variational Autoencoders (VQ-VAE) are trained for facial, bodily, and hand motions, thereby optimizing motion tokenizer performance with multiple loss functions."
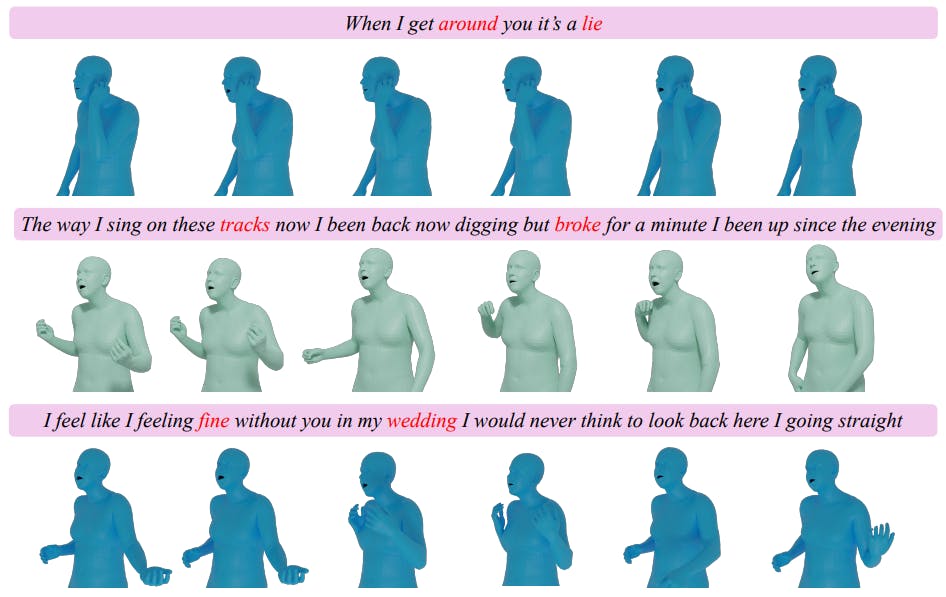
A supplementary website demo illustrates the generation quality of the proposed system with vivid qualitative results. The motion tokenizer employs three separate Vector Quantized Variational Autoencoders (VQ-VAE) trained for face, body, and hand gestures using various loss functions. An optimized system utilizes strategies like codebook reset and exponential moving average for training. Additionally, a semantic encoder based on HuBERT transforms audio input into a 768-dimensional vector space, employing k-means with 500 centroids for quantization to represent discrete content codes.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]