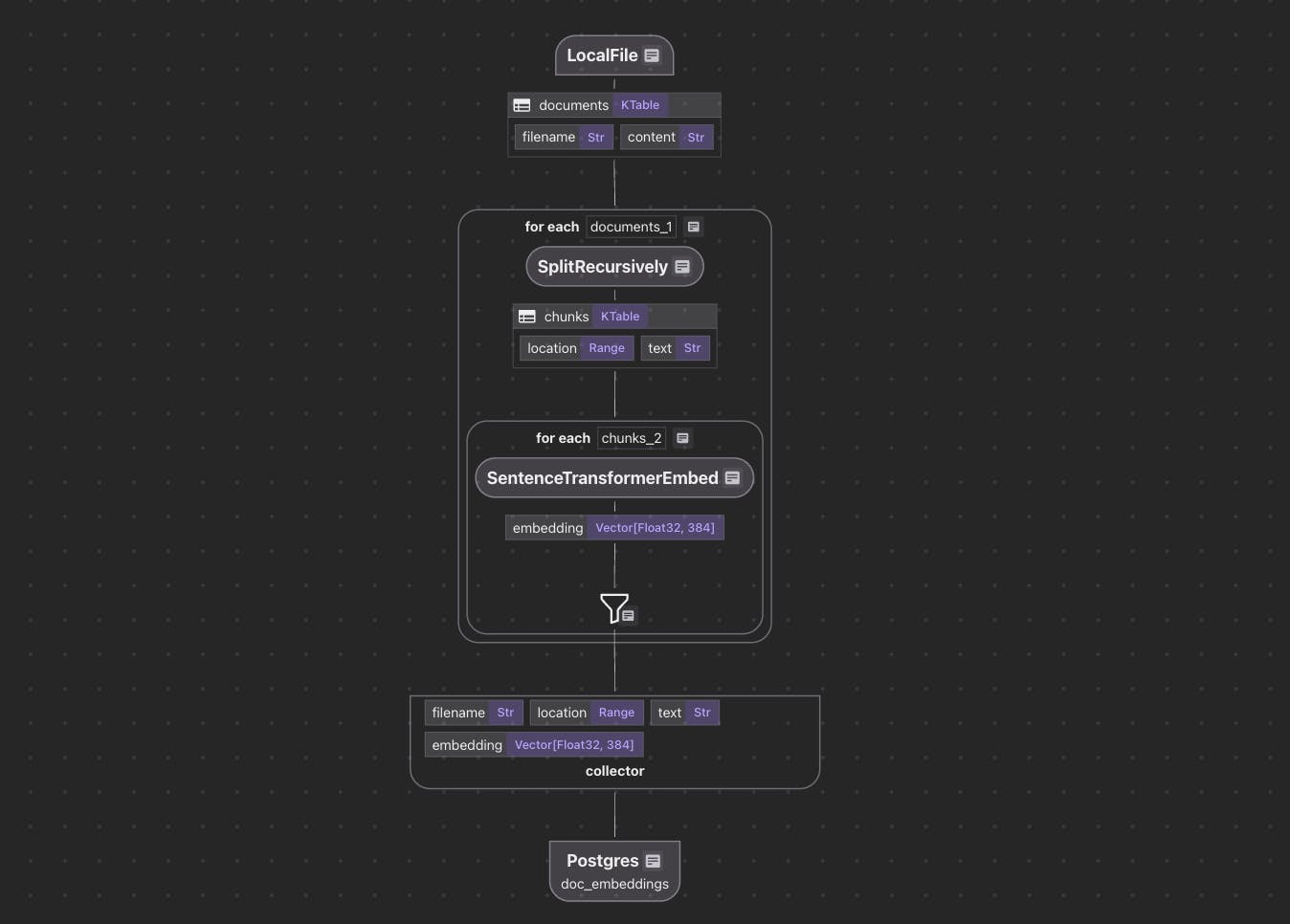
"I try to make change detection a first-class part of the pipeline: Hashes of source content, Timestamps or version numbers, Diffing at the chunk or field level."
"This avoids brute-force reprocessing and sets up the foundation for safe, incremental updates."
Managing indexing systems is complex, particularly during significant changes in data schemas or models. Unlike easier-to-reset analytics jobs, indexing systems must preserve state and relationships. The author emphasizes treating the indexing state as durable, making change detection explicit, and defining what updates can be safely reprocessed. For large-scale systems, leveraging mechanisms like source content hashes and timestamps ensures efficient and consistent processing, reducing unnecessary rework and preserving downstream functionality.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]