Uber's Hive data warehouse has been redesigned to decentralize over 16,000 datasets, totaling more than 10 petabytes. This change addresses scalability, operational, and security challenges. The previous monolithic structure created risks such as cascading outages and governance bottlenecks. The new federated approach allows for independent scaling of domain-specific datasets while maintaining high availability and enforcing least-privilege access. A pointer-based migration method enables seamless dataset relocation without data duplication, ensuring continuous operation for critical workloads during the transition.
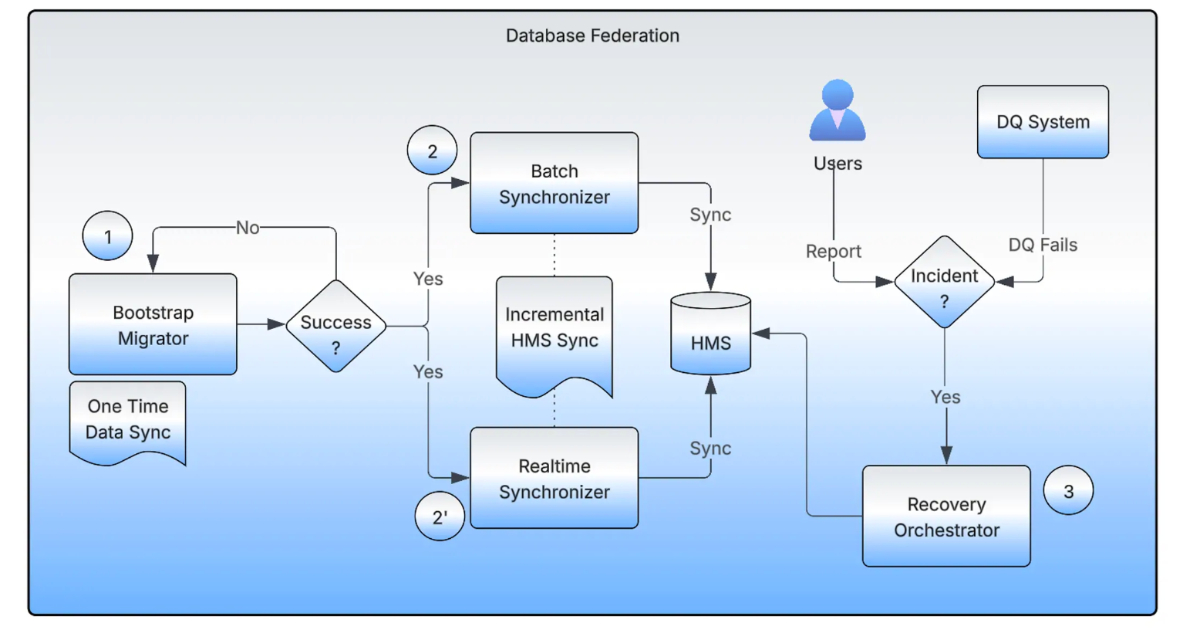
"Updating a dataset pointer in HMS is a split-second operation, ensuring continuous functioning for critical workloads. This approach ensures zero downtime for analytics jobs and machine learning pipelines dependent on Hive."
"The Bootstrap Migrator manages the initial dataset movement, using distributed Spark jobs and checksum verification to validate completeness. Real-time and Batch Synchronizers maintain metadata alignment between source and target during migration."
"The Recovery Orchestrator tracks pointer backups, enabling safe rollback if inconsistencies are detected. These human-in-the-loop validations and automated checks enable teams to perform migrations with confidence."
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]