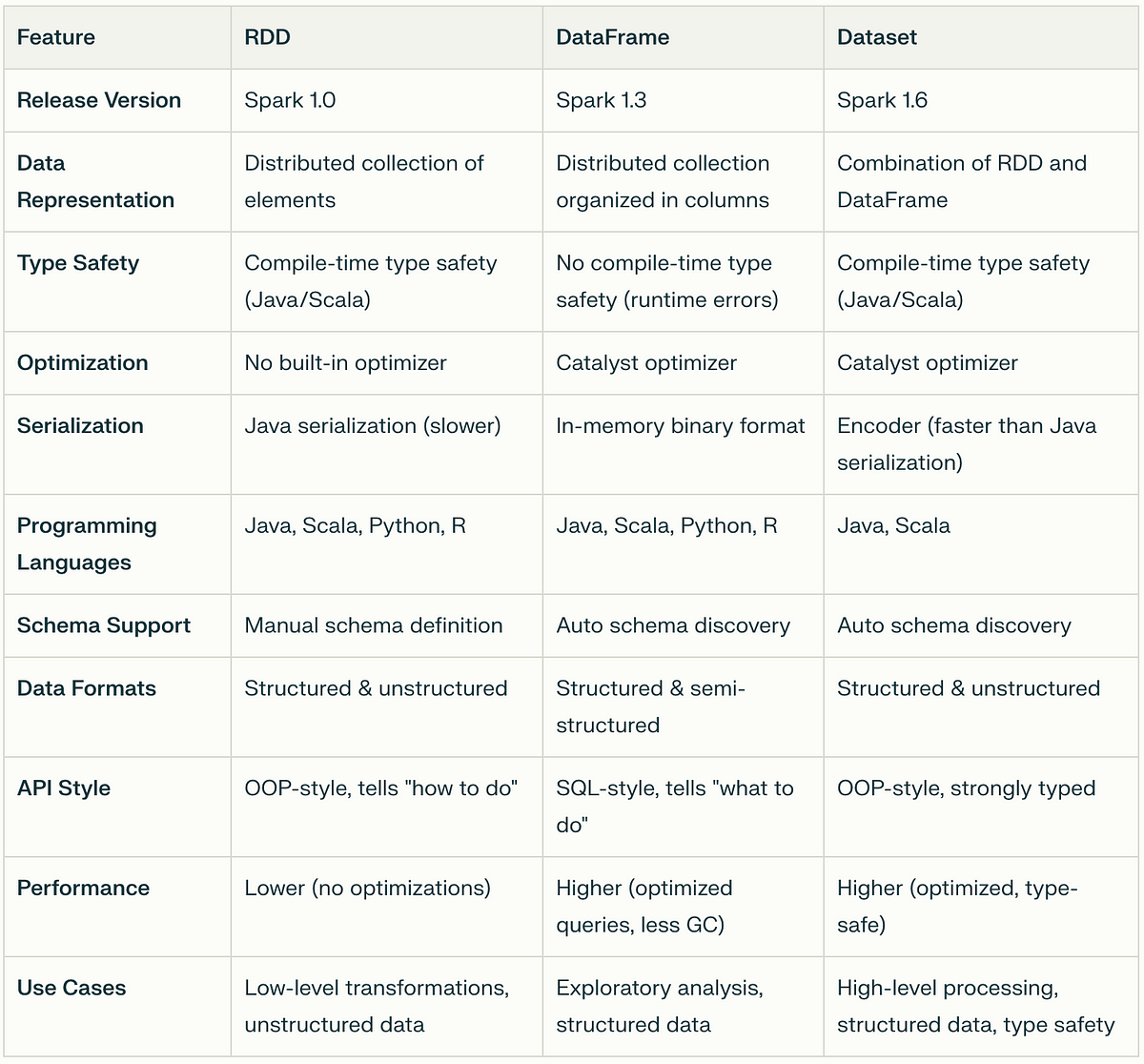
"Spark offers three main APIs—RDD, DataFrame, and Dataset—each with unique advantages: RDD provides low-level control, DataFrames optimize performance, and Datasets bring type safety."
"RDDs are the building blocks of Spark, allowing for flexible transformations but at the cost of lower performance compared to DataFrames which leverage Catalyst optimization."
Apache Spark has three key APIs for big data processing: RDDs, DataFrames, and Datasets. RDDs are the lowest-level, immutable collections that provide fine-grained control but lack optimization. DataFrames offer structured data handling and optimized performance through the Catalyst engine, suitable for users familiar with SQL. Datasets bring type safety to DataFrames and combines their performance benefits with the functional programming features of RDDs, but are limited to Scala and Java. This comparison clarifies when to use each API effectively in practical scenarios.
Read at Medium
Unable to calculate read time
Collection
[
|
...
]