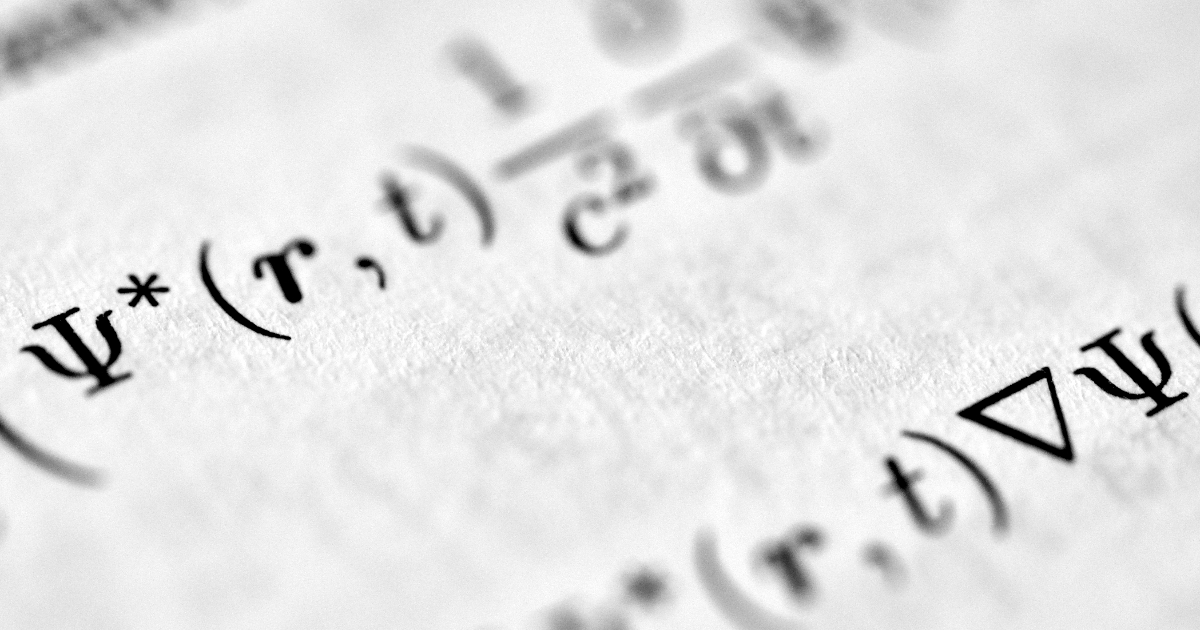
"TurboQuant can compress the KV cache down to 3.5 bits per value with near-zero accuracy loss. On standard benchmarks like LongBench and Needle in a Haystack, a 3.5-bit TurboQuant implementation matched the performance of full 16-bit precision across Gemma and Mistral models."
"TurboQuant uses a two-step approach. First, data vectors are rotated using a randomized Hadamard transform, which preserves key Euclidean properties while spreading out values. This transformation helps in removing the outlier-heavy coordinate distribution that complicates low-bit quantization."
"Post-transform, the vector coordinates follow a beta distribution that is more amenable to compression with low distortion. The second step applies the Quantized Johnson-Lindenstrauss transform to eliminate bias from the first step, ensuring that inner products between quantized vectors remain accurate estimators of unquantized vectors."
TurboQuant is a new quantization algorithm that compresses Key-Value caches in large language models by up to 6x while maintaining near-zero accuracy loss. It allows developers to utilize larger context windows on less powerful hardware. The algorithm employs a two-step approach involving a randomized Hadamard transform and the Quantized Johnson-Lindenstrauss transform to ensure accurate inner product estimations. Early benchmarks indicate significant efficiency gains, with community analyses suggesting realistic improvements of 30-40% in memory reduction and processing speed compared to previous methods.
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]