"One of the most frequent debates I encounter is: 'Should we use PySpark or Scala for Spark development?' This decision impacts performance, maintainability, and overall development efficiency."
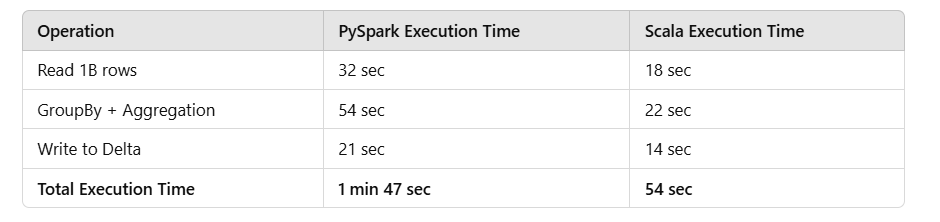
"While PySpark is easier for Python developers, it can introduce performance bottlenecks that may hinder development. In contrast, Scala, being optimized for Spark, offers better performance but requires a steeper learning curve."
In data engineering, the choice between PySpark and Scala is crucial. While PySpark offers ease of use for Python developers, it may lead to performance bottlenecks, thus impacting overall efficiency. Conversely, Scala is the native language for Spark, providing superior performance but with a more complex learning curve. This article draws from real-world experiences in optimizing workloads within Databricks, emphasizing the importance of selecting the appropriate language based on project needs, particularly in areas like memory usage and ease of maintainability.
Read at Medium
Unable to calculate read time
Collection
[
|
...
]