"We delved into the five pretraining datasets of 34 multimodal vision-language models, analyzing the distribution and composition of concepts within, generating over 300GB of data artifacts that we publicly release."
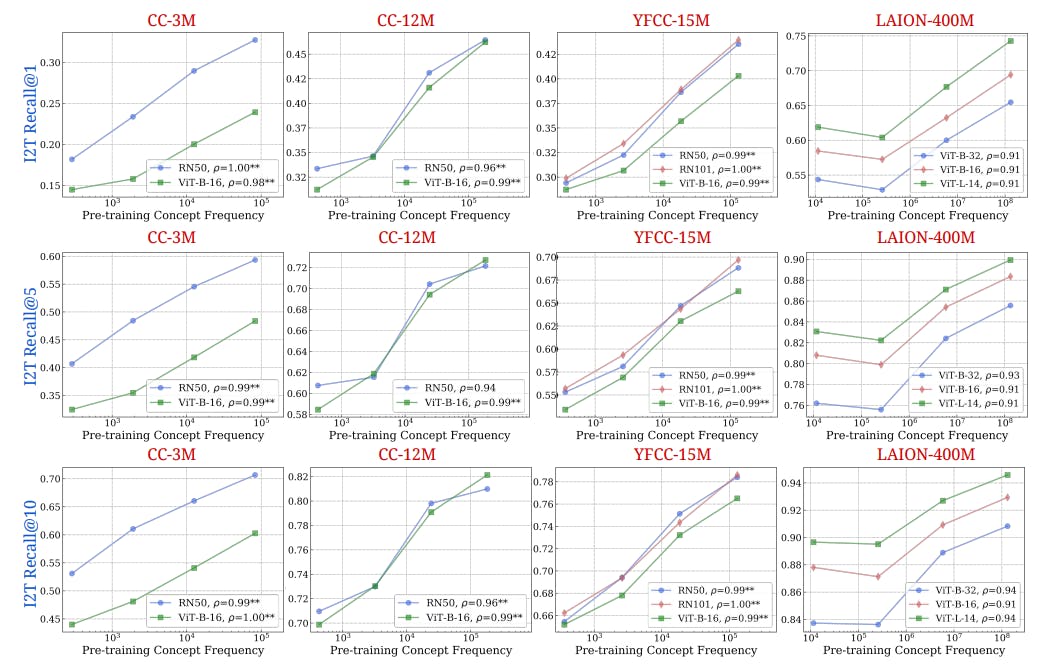
"Our findings reveal that across concepts, significant improvements in zero-shot performance require exponentially more data, following a log-linear scaling trend."
"This pattern persists despite controlling for similarities between pretraining and downstream datasets or even when testing models on entirely synthetic data distributions."
"Further, all tested models consistently underperformed on the 'Let it Wag!' dataset, which we systematically constructed from our findings to test long-tail concepts."
Analysis of five pretraining datasets from 34 multimodal vision-language models was conducted to explore the distribution and composition of concepts. The study generated over 300GB of data artifacts for public release. Findings indicate that substantial improvements in zero-shot performance necessitate exponentially more data, reflecting a log-linear scaling trend. This trend holds true even after controlling for dataset similarities and when using purely synthetic data distributions. All models exhibited consistent underperformance on the 'Let it Wag!' dataset, designed to evaluate long-tail concepts.
#pretraining-data #zero-shot-performance #multimodal-models #long-tail-concepts #data-scaling-trends
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]