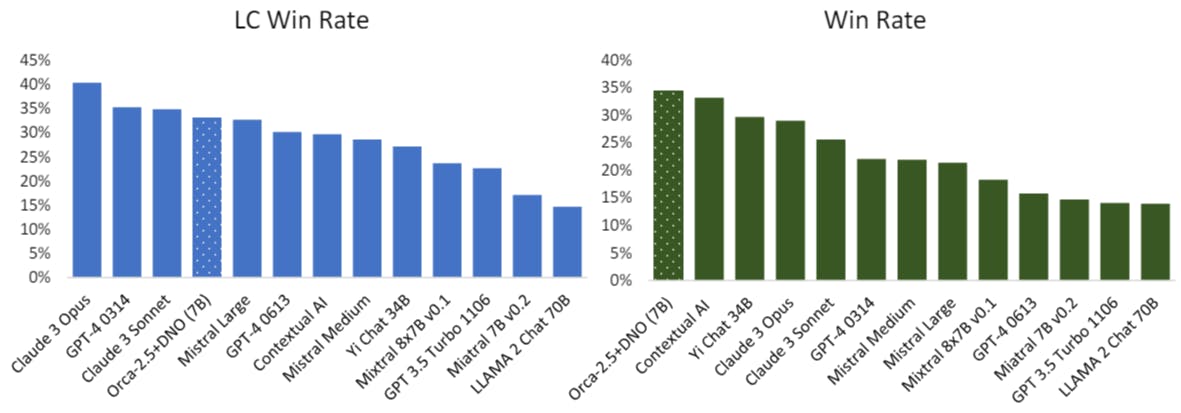
"This paper introduces Direct Nash Optimization (DNO), a novel approach that integrates stability and generality in large language model post-training, moving beyond traditional reward maximization limits."
"The approach in this paper focuses on pair-wise preference optimization which allows for more complex preference relationships compared to the conventional point-wise reward systems."
"Our experiments demonstrate that models optimized through DNO exhibit significant performance improvements over traditional reinforcement learning methodologies, highlighting the effectiveness of preference-based training."
"The theoretical foundations laid out show that combining contrastive learning with direct preference optimization leads to robust language models that better reflect complex human preferences."
The paper explores advancements in post-training large language models (LLMs) by utilizing preference feedback for iterative self-improvement. It introduces Direct Nash Optimization (DNO), an innovative approach merging stability from contrastive learning with the flexibility of optimizing general preferences. By addressing limitations of traditional Reinforcement Learning from Human Feedback (RLHF) which relies heavily on point-wise rewards, DNO enhances the model's ability to handle complex, cyclical preference relations. Experiments indicate that this method results in notable performance improvements, suggesting a transformative step in preference-based language model training methodologies.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]