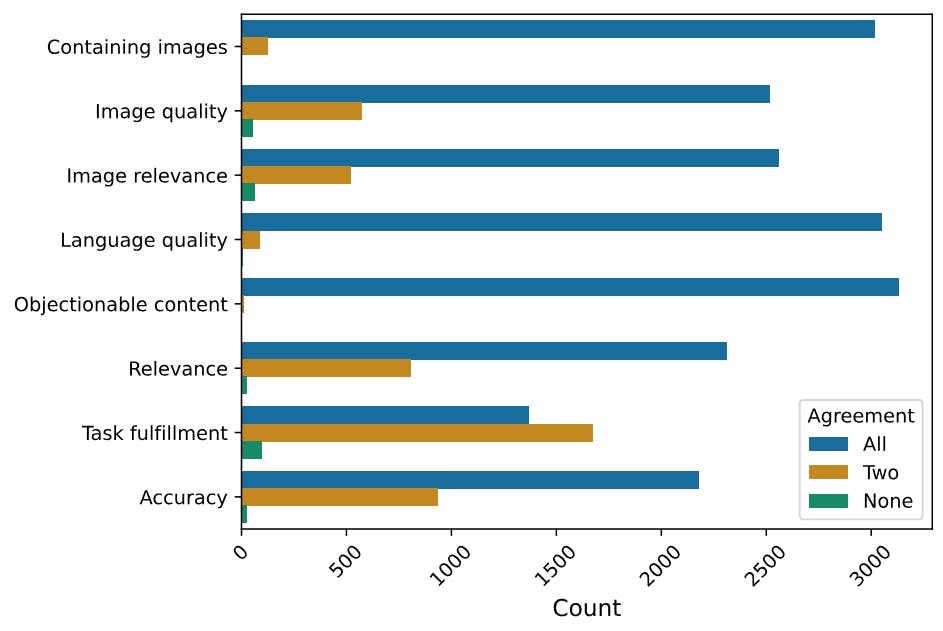
"In our evaluation, questions are answered by three human annotators, and we consider majority votes the final answer to ensure reliability in our results."
"The agreement level among annotators is high for objective property evaluations, indicating a reliable agreement on whether responses contain objectionable content."
"For evaluations on task fulfillment, disagreements can occur, but they tend to be minor, reflecting nuanced judgments rather than outright contradictions among annotators."
"Around 28% to 35% of responses see unanimous agreement among annotators, while approximately 55% to 60% experience some level of disagreement, indicating evaluation complexity."
The article discusses the methodology and findings of a human evaluation study assessing model outputs. Each question was reviewed by three annotators, whose consensus determined the final judgment. High levels of agreement were observed for objective assessments like identifying objectionable content, suggesting reliable evaluative practices. Discrepancies mainly occurred on subjective tasks, yet they were minor. Statistical results revealed that about 28% to 35% of cases had unanimous agreement, indicating some inconsistency, yet suggesting nuanced evaluations of model performance in different contexts.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]