"This study highlights the critical issue of bias amplification in large language models (LLMs), demonstrating its impact predominantly through the lens of political bias in U.S. media."
"While the identified mitigation strategies, such as Preservation and Accumulation, offer promise in addressing bias amplification, challenges regarding computational costs and real-world applicability remain significant."
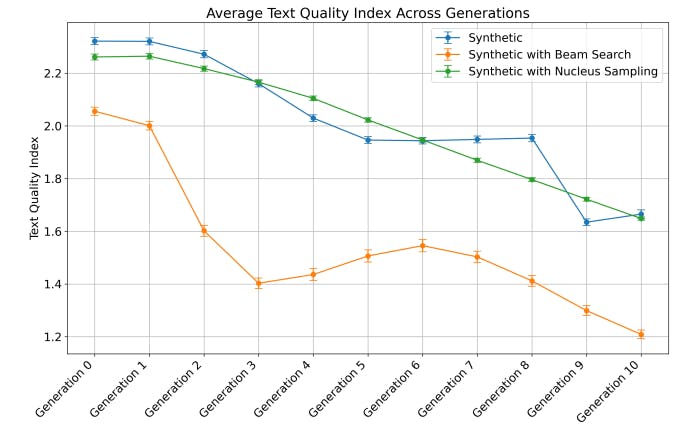
The article presents a comprehensive framework for understanding bias amplification in large language models (LLMs), specifically focusing on political biases through empirical studies utilizing GPT-2. It underscores the significant ethical implications associated with bias amplification, especially when LLMs are trained on synthetic data. While certain mitigation strategies show promise, challenges such as computational costs and the need for validation in real-world scenarios are acknowledged. The scope of research is limited to U.S. media bias and calls for broader explorations across various contexts and larger models like GPT-4 or LLaMA2.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]