"In our evaluations, we aggregate responses based on human perception of clarity and expectation for mixed-modal outputs, refining our prompts through majority vote analysis."
"By employing a diverse set of prompts, we assess the multi-modal language model's capacity to generate coherent and contextually appropriate responses across varied real-life scenarios."
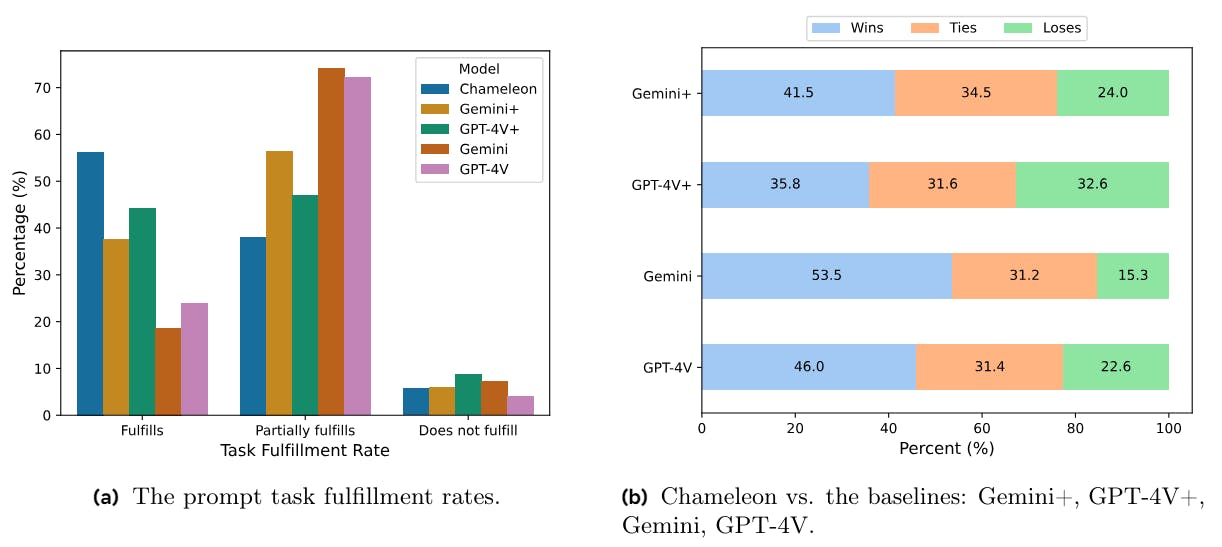
The article discusses the evaluation of the Chameleon model's multi-modal understanding and generation capabilities through extensive human evaluations. It describes the process of gathering diverse prompts from annotators, who are tasked with formulating questions based on everyday scenarios requiring mixed-modal outputs (text and images). These prompts undergo a filtering process to ensure clarity and appropriateness, allowing a structured assessment of the model's responses. A safety study is integrated to ensure that the model operates safely in practical applications.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]