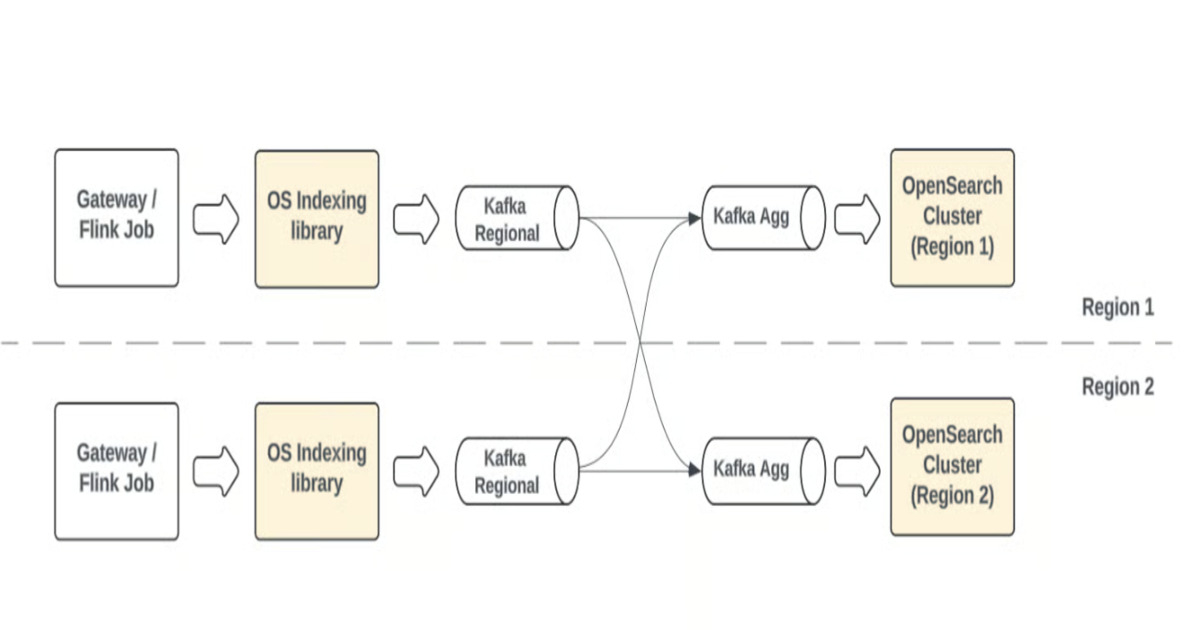
"Uber has moved its in-house search indexing system to OpenSearch by introducing a pull-based ingestion framework for large-scale streaming data. The change goal was to improve reliability, backpressure handling, and recovery for real-time indexing workloads, after evolving product requirements revealed the growing cost and complexity of maintaining a homegrown search platform, including challenges around schema evolution, relevance tuning, and multi-region consistency."
"Pull-based ingestion shifts responsibility to the OpenSearch cluster. Shards pull data from durable streams such as Kafka or Kinesis, which act as buffers, allowing controlled rates, internal backpressure, and replay for recovery. Uber engineers report that this approach reduces indexing failures during spikes and simplifies operational recovery. Bursty traffic that previously overwhelmed shard queues is now absorbed by per-shard bounded queues, improving throughput and stability."
Uber moved its in-house search indexing to OpenSearch and introduced a pull-based ingestion framework for large-scale streaming data. The change aimed to improve reliability, backpressure handling, and recovery for real-time indexing after homegrown platform costs and complexities grew. The new architecture maps shards to durable stream partitions (Kafka or Kinesis) so shards pull messages into per-shard bounded queues. A stream consumer decouples consumption from processing by polling into a blocking queue and enabling parallel writers. Separate threads validate, transform, and prepare indexing requests. The ingestion engine writes directly to Lucene, enabling controlled rates, replay, and simpler operational recovery.
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]