"A cron job loops over all titles in all blog posts and finds portions of the words in the titles as singles, doubles, and triples. For each one, the popularity of the blog post is accumulated to the extracted keywords and combos. These are then inserted into a Django ORM model that looks like this: class SearchTerm(models.Model): term = models.CharField(max_length=100, db_index=True) popularity = models.FloatField(default=0.0) add_date = models.DateTimeField(auto_now=True) index_version = models.IntegerField(default=0) class Meta: unique_together = ("term", "index_version") indexes = [ GinIndex( name="plog_searchterm_term_gin_idx", fields=["term"], opclasses=["gin_trgm_ops"], ), ]"
"The index_version is used like this, in the indexing code: current_index_version = ( SearchTerm.objects.aggregate(Max("index_version"))["index_version__max"] or 0 ) index_version = current_index_version + 1 ... SearchTerm.objects.bulk_create(bulk) SearchTerm.objects.filter(index_version__lt=index_version).delete() That means that I don't have to delete previous entries until new ones have been created. So if something goes wrong during the indexing, it doesn't break the API. Essentially, there are about 13k entries in that model. For a very brief moment there are 2x13k entries and then back to 13k entries when the whole task is done."
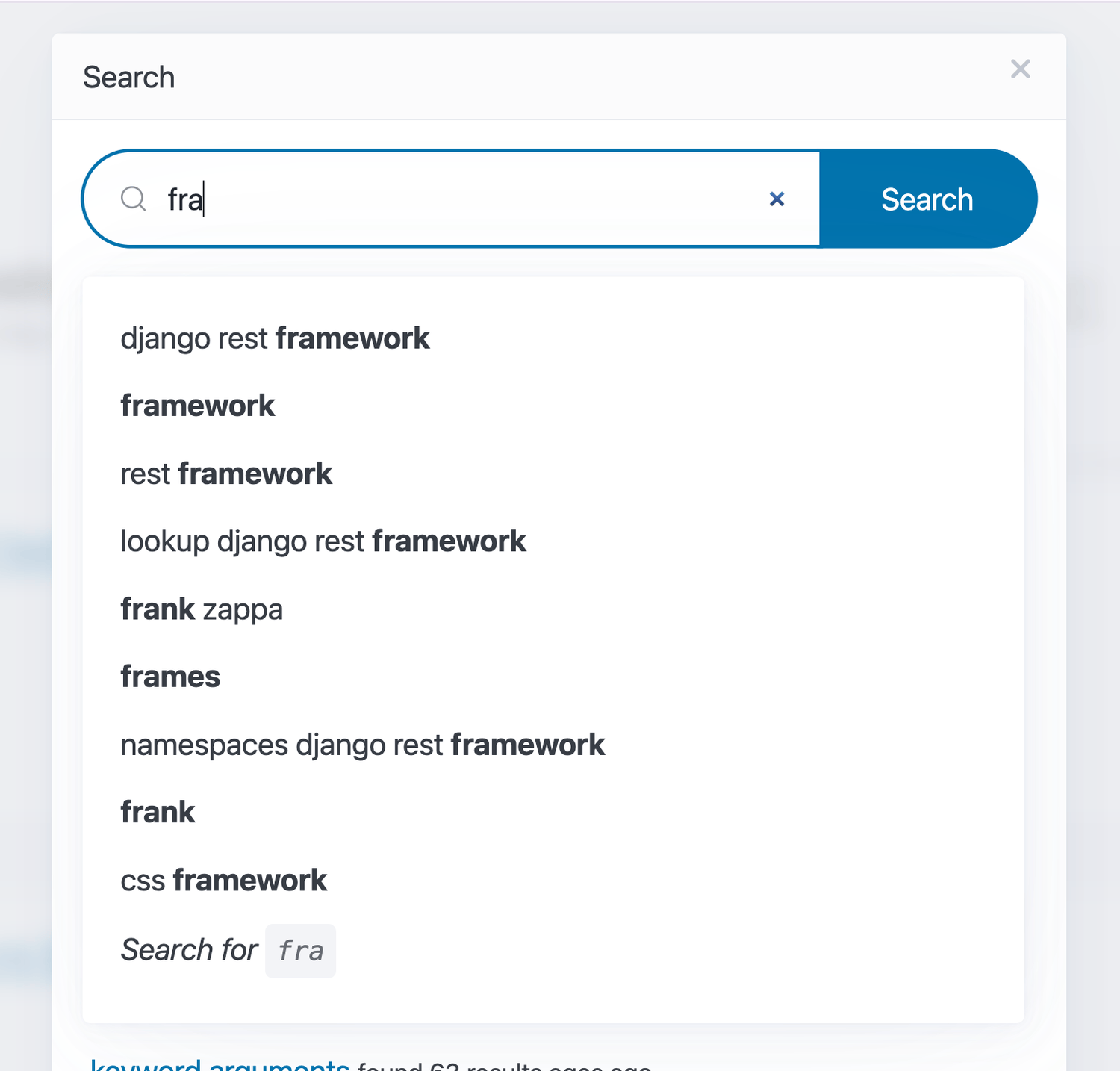
A cron job iterates all blog post titles and extracts single, double, and triple-word segments. Popularity scores from each blog post are aggregated onto those extracted keywords and n-grams. The aggregated entries are stored in a Django SearchTerm model with fields for term, popularity, add_date, and index_version, plus a GIN trigram index on the term column. Indexing increments the index_version, bulk-creates new entries, then deletes older versions to avoid downtime during rebuilds. The typeahead API performs prefix matching using SQL LIKE against the term column for autocomplete responses.
Read at Peterbe
Unable to calculate read time
Collection
[
|
...
]