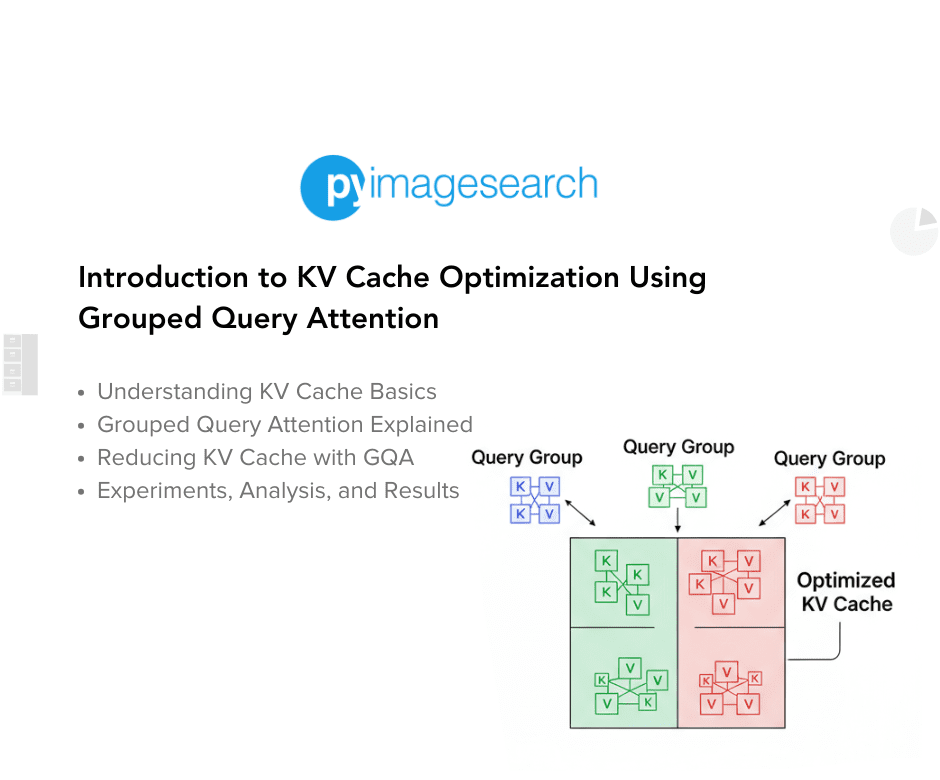
"At the heart of this challenge lies the key-value (KV) cache, which stores every past key and value tensor for each attention head, thereby avoiding redundant computations. While caching accelerates per-token generation, its memory footprint scales linearly with the number of attention heads, sequence length, and model depth. Left unchecked, KV cache requirements can balloon to tens of gigabytes, forcing trade-offs in batch size or context length."
"Grouped Query Attention (GQA) offers a middle ground by reassigning multiple query heads to share a smaller set of KV heads. This simple yet powerful adjustment reduces KV cache size without a substantial impact on model accuracy. In this post, we'll explore the fundamentals of KV cache, compare attention variants, derive memory-savings math, walk through code implementations, and share best-practice tips for tuning and deploying GQA-optimized models."
Large language models process long contexts to support coherent essays, multi-step reasoning, and extended conversations, but autoregressive decoding intensifies computational and memory demands as sequence lengths increase. The KV cache stores past key and value tensors for each attention head to avoid redundant recomputation, yet its memory usage grows linearly with attention heads, sequence length, and model depth. Grouped Query Attention reassigns multiple query heads to a smaller set of KV heads, cutting KV cache size while preserving model accuracy. Practical deployment requires trading off context length, batch size, and hardware limits and tuning GQA parameters for optimal inference.
Read at PyImageSearch
Unable to calculate read time
Collection
[
|
...
]