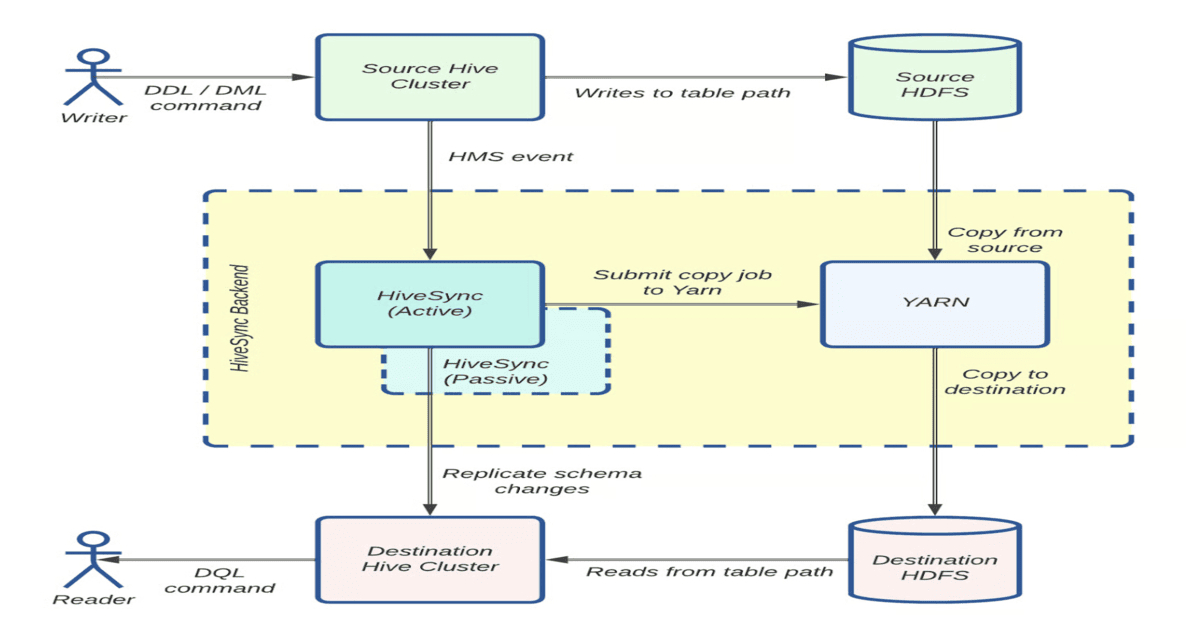
Uber's engineering team rebuilt its data replication platform to manage petabytes of data daily across hybrid cloud and on-premise data lakes. Built on Hadoop's open-source Distcp framework, the platform now processes over one petabyte daily with hundreds of thousands of jobs. HiveSync, originally based on Airbnb's ReAir project, synchronizes HDFS and cloud data lakes through bulk and incremental replication. As daily replication grew from 250 TB to over 1 PB and datasets expanded from 30,000 to 144,000, the team faced scaling challenges threatening service level agreements. Optimizations included moving resource-intensive tasks like Copy Listing and Input Splitting from the HiveSync server to the Application Master, parallelizing processes, and improving efficiency for small transfers.
"Uber's engineering team has transformed its data replication platform to move petabytes of data daily across hybrid cloud and on-premise data lakes, addressing scaling challenges caused by rapidly growing workloads. Built on Hadoop's open-source Distcp framework, the platform now handles over one petabyte of daily replication and hundreds of thousands of jobs with improved speed, reliability, and observability."
"Distcp is an open-source framework that copies large datasets in parallel across multiple nodes using Hadoop's MapReduce. Files are split into blocks and assigned to Copy Mapper tasks running in YARN containers. The Resource Manager allocates resources, the Application Master monitors job execution and coordinates merges, and the Copy Committer assembles final files at the destination."
"HiveSync, originally based on Airbnb's ReAir project, keeps Uber's HDFS and cloud data lakes synchronized using bulk and incremental replication. For datasets larger than 256 MB, it submits Distcp jobs through asynchronous workers in parallel, with a monitoring thread tracking progress. As daily replication grew from 250 TB to over 1 PB and datasets expanded from 30,000 to 144,000, HiveSync faced backlogs that threatened SLAs."
#data-replication #distributed-systems #cloud-infrastructure #hadoop-optimization #petabyte-scale-data
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]