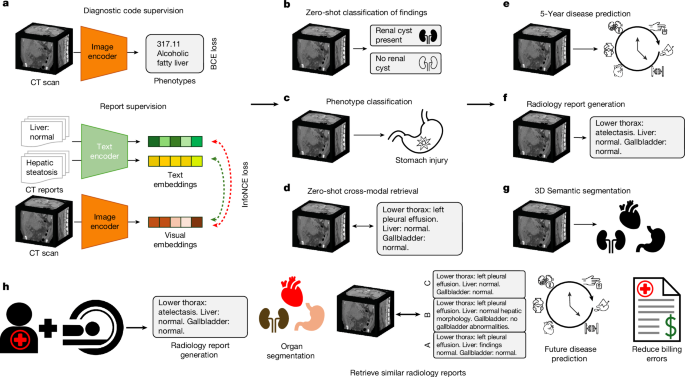
The increasing volume of abdominal CT scans combined with a shortage of radiologists has created urgent demand for automated medical image analysis tools. Vision-language models that jointly process images and radiology reports represent the current state-of-the-art approach for automated analysis. However, existing medical VLMs face significant limitations, as they are generally restricted to analyzing 2D images and processing short reports, which constrains their effectiveness in handling complex clinical scenarios.
"The large volume of abdominal computed tomography (CT) scans coupled with the shortage of radiologists have intensified the need for automated medical image analysis tools. Previous state-of-the-art approaches for automated analysis leverage vision-language models (VLMs) that jointly model images and radiology reports."
"Current medical VLMs are generally limited to 2D images and short reports, indicating significant constraints in their capability to process comprehensive clinical data and three-dimensional imaging information necessary for thorough diagnostic analysis."
#medical-image-analysis #vision-language-models #ct-imaging #automated-diagnosis #radiologist-shortage
Read at Nature
Unable to calculate read time
Collection
[
|
...
]