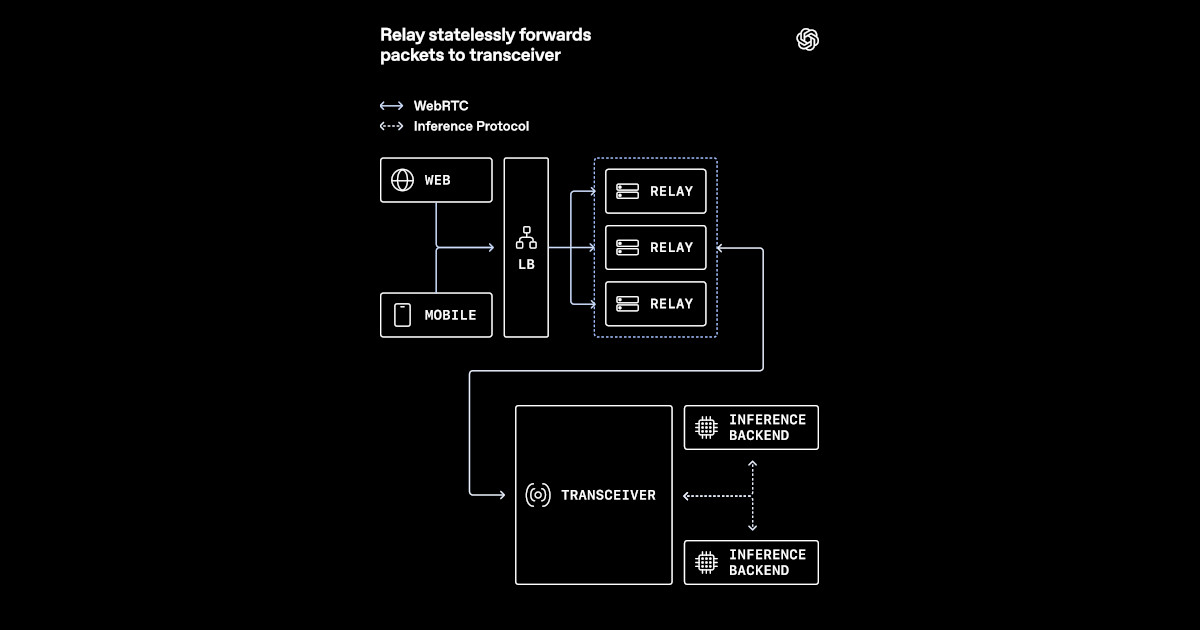
OpenAI adapted WebRTC for low-latency voice AI at global scale by replacing a conventional media termination model with a relay-transceiver design. The approach targets global reach, fast connection setup, and low, stable media round-trip times. Direct per-session UDP exposure was considered but increases infrastructure complexity in Kubernetes, where managing large public port ranges is difficult and leads to port planning, uneven utilization, and brittle rollouts. TURN-style relays were also evaluated, but they add a heavier intermediary and solve a broader problem than needed for mostly 1:1 sessions. The chosen design separates responsibilities: a lightweight relay forwards packets, while a dedicated transceiver layer handles ICE negotiation, DTLS handshakes, SRTP encryption, and the full session lifecycle.
"OpenAI recently outlined how it adapted WebRTC for low-latency voice AI at global scale. The new architecture replaced a conventional media termination model with a relay-transceiver design better suited to Kubernetes and cloud load balancers. It keeps WebRTC session state in a dedicated transceiver layer while using lightweight relays to reduce public UDP exposure and keep media routing close to users."
"The first alternative was direct per-session UDP exposure, which preserves the conventional WebRTC model. However, it pushes operational complexity into the infrastructure layer, especially in Kubernetes environments, where large public port ranges are difficult to manage safely. Allocating unique ports per server simplifies some routing decisions, but still leaves operators dealing with port planning, uneven utilisation, and more brittle rollout patterns."
"TURN-style relays were also a plausible option, but they introduce a heavier intermediary into the media path and solve a wider problem than OpenAI needed for predominantly 1:1 model-to-user sessions. OpenAI instead chose to split responsibilities between two layers. A lightweight relay accepts incoming packets and forwards them, while a separate transceiver owns all of the stateful WebRTC machinery, including ICE negotiation, DTLS handshakes, SRTP encryption, and overall session lifecycle."
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]