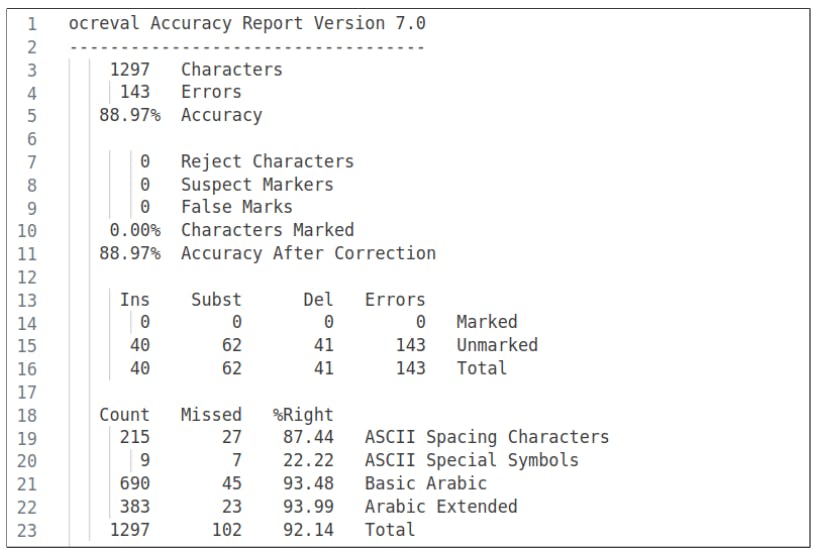
"The limited availability of resources posed significant challenges during our data collection process. Converting the collected data into a digital format proved an additional obstacle. Manual transcription of the documents was difficult due to unclear text, non-standard spacing, and unique vocabulary influenced by Arabic letters and terminologies. We attempted to create the dataset synthetically, crafting a small tool that assembled letters from a given collection of character images. Regrettably, the outcomes were unsatisfactory, and given our time constraints, we discontinued this approach."
"The non-standard spacing between the words and characters was challenging for transcribing the documents and needed to be more apparent for the model. The model interpreted the excessive gaps between characters or words as space characters. In contrast, in other cases where there should have been a space character, the minimal spacing went unnoticed by the model. Extracting text from multi-column pages was another limitation of the model."
Data collection encountered severe constraints from limited resources and difficulties converting materials to digital form. Manual transcription struggled with unclear text, non-standard spacing, and unique vocabulary influenced by Arabic letters and terminologies. A synthetic dataset approach assembling letters from character images produced unsatisfactory outcomes and was discontinued due to time constraints. The model misinterpreted excessive gaps as spaces and missed minimal spacing, degrading word boundary detection. Multi-column layouts and mathematical equation recognition remained problematic. Future efforts prioritize dataset expansion and improved handling of spacing, layout segmentation, and equation recognition.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]