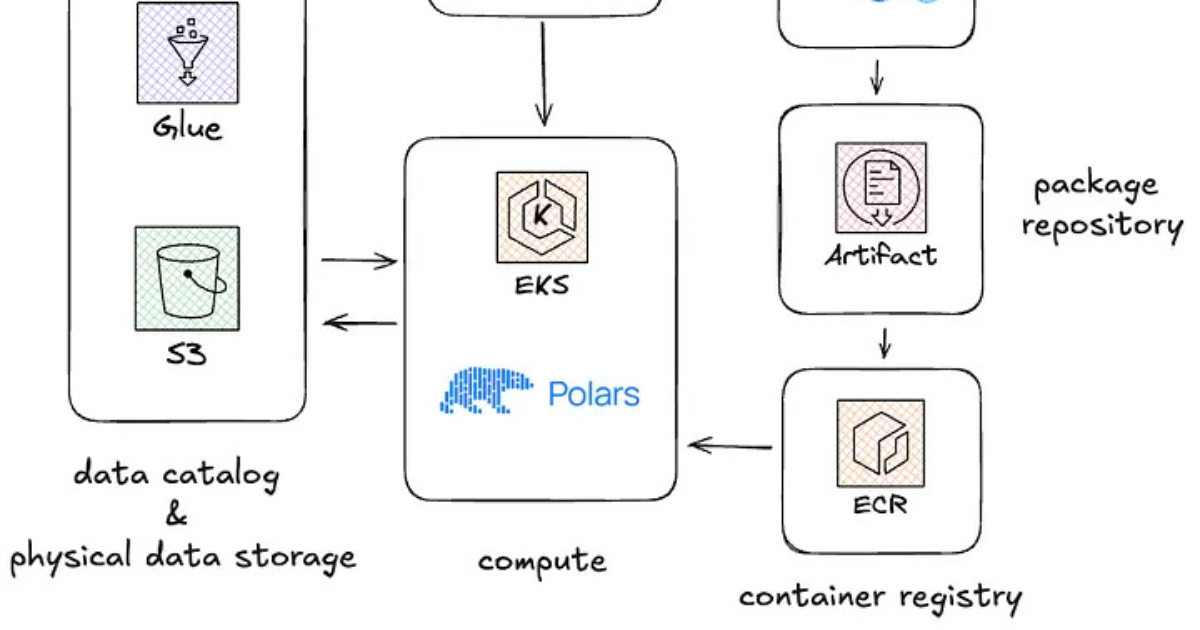
Decathlon runs PySpark workflows on cloud clusters sized around 180 GiB of RAM and 24 cores across six workers. Data resides as Delta tables in an AWS S3 data lake with AWS Glue as the metastore. The platform applies a Medallion-style architecture (Bronze, Silver, Gold, Insight) and uses MWAA for orchestration plus GitHub Actions for CI/CD. Many workflows process gigabytes or megabytes rather than terabytes, making large Spark clusters inefficient for those jobs. The team adopted Polars, a Rust-based OLAP engine using Apache Arrow, to replace pandas and migrate smaller Spark jobs to single-node Kubernetes pods for speed and cost savings.
"Decathlon's data platform runs PySpark workflows on cloud clusters, each with approximately 180 GiB of RAM and 24 cores across six workers. Data is stored as Delta tables in an AWS S3 data lake, with AWS Glue serving as the technical metastore. While the solution was optimized for large data jobs, it was considered suboptimal for much smaller datasets (gigabytes or megabytes)."
"For data engineers in the data department, the primary tool is Apache Spark, which excels at processing terabytes of data. However, it turns out that not every workflow has terabytes of data as input; some involve gigabytes or even megabytes. The platform uses a Medallion-style architecture (Bronze, Silver, Gold, Insight) to refine and organize data for quality and governance."
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]