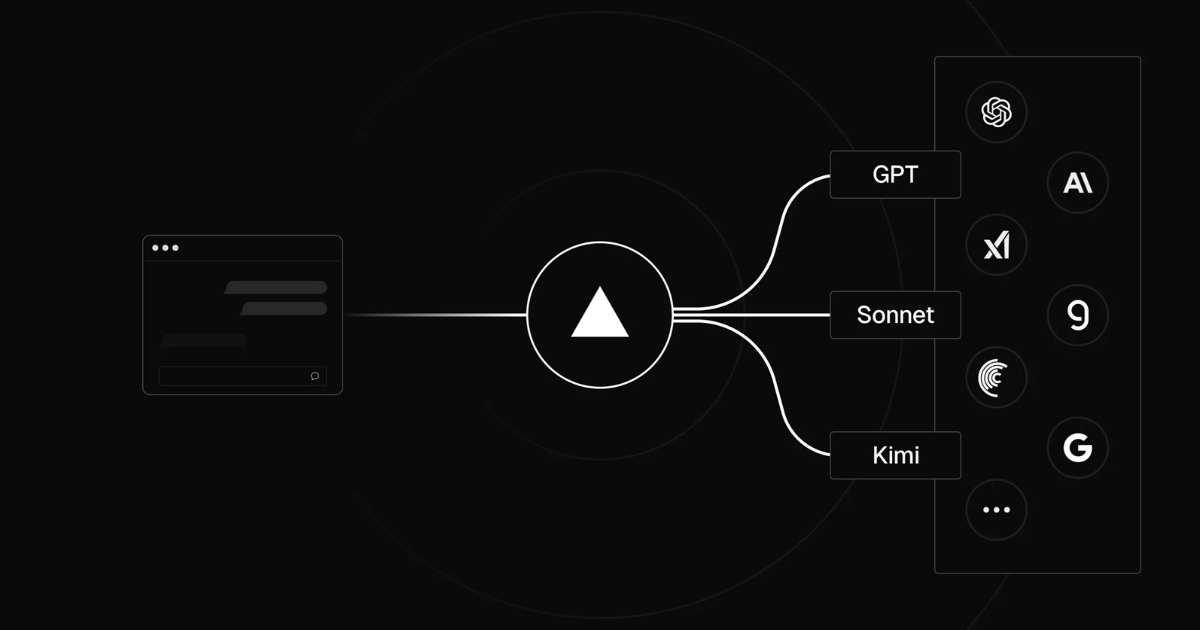
"Vercel has rolled out the AI Gateway for production workloads. The service provides a single API endpoint for accessing a wide range of large language and generative models, aiming to simplify integration and management for developers. The AI Gateway allows applications to send inference requests to multiple model providers through one endpoint. It supports bring-your-own-key authentication, which means developers can use their own API keys from providers such as OpenAI, Anthropic, or Google without paying an additional token markup."
"The gateway also provides consistent request routing with latency under 20 milliseconds, designed to keep inference times stable regardless of the underlying provider. One of the core features of the system is its failover mechanism. If a model provider experiences downtime, the gateway automatically redirects requests to an available alternative, reducing service interruptions. It also supports high request throughput, with rate limits intended to meet production-level traffic."
"Observability is built into the platform. Developers have access to detailed logs, performance metrics, and cost tracking for each request. This data can be used to analyze usage patterns, monitor response times, and understand the distribution of costs across different model providers. Integration can be done using the AI SDK, where a request can be made by specifying a model identifier in the configuration. Vercle highlighted that the AI Gateway has been in use internally to run v0.app, a service that has served millions of users."
Vercel provides a unified AI Gateway that exposes a single API endpoint to access many large language and generative models. The platform supports bring-your-own-key authentication so developers can use provider API keys without extra token markups. The gateway enforces consistent routing with latency under 20 milliseconds and includes automatic failover to maintain availability when a provider is down. The service supports high throughput and production-oriented rate limits. Built-in observability supplies logs, performance metrics, and per-request cost tracking. Integration uses an AI SDK with model identifiers. The infrastructure has been used internally to serve millions of users and is now available externally.
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]