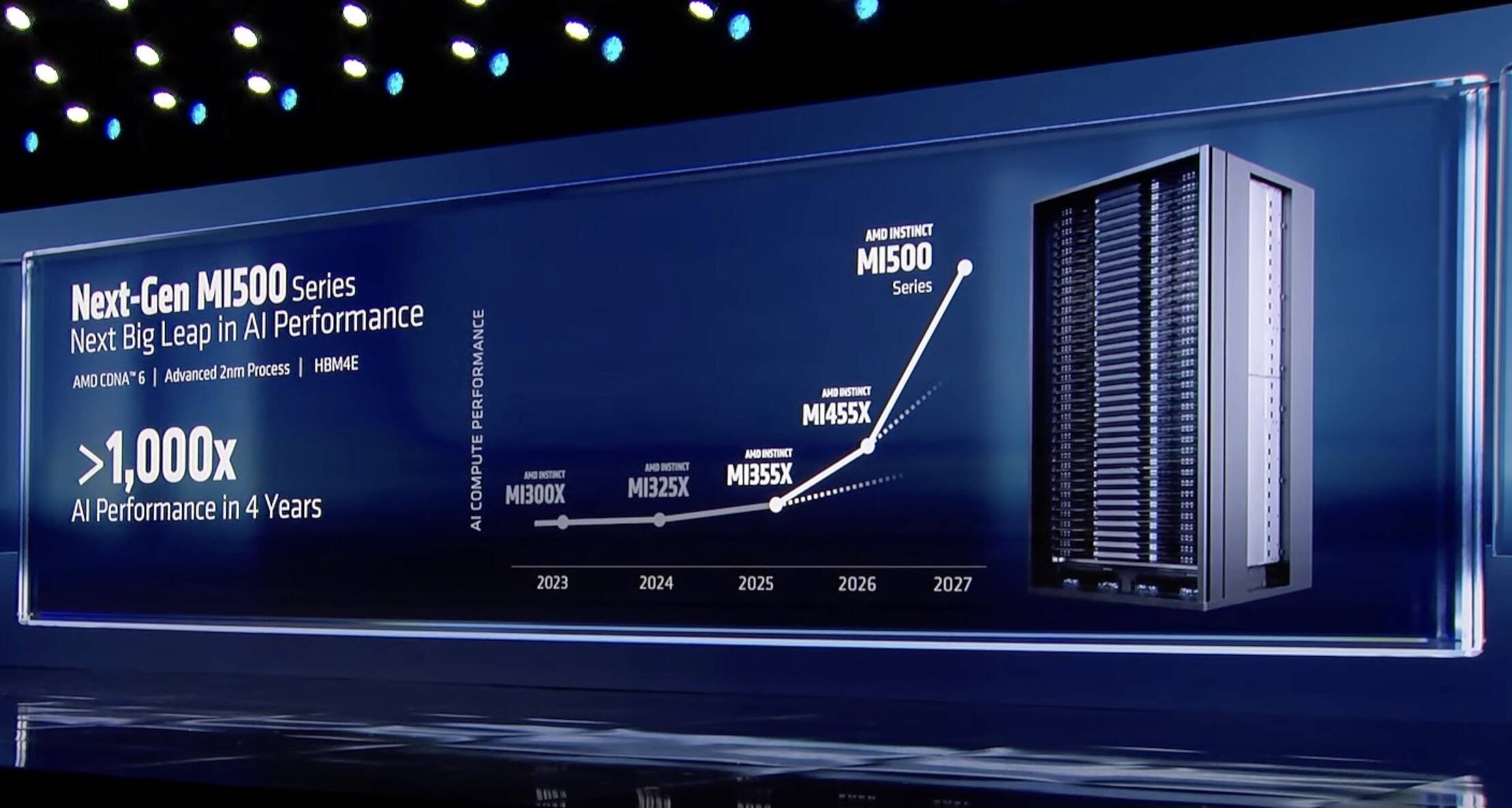
"AMD clarified those estimates are based on a comparison between an eight-GPU MI300X node and an MI500 rack system with an unspecified number of GPUs. The math works out to eight MI300Xs that are 1000x less powerful than X-number of MI500Xs. And since we know essentially nothing about the chip besides that it'll ship in 2027, pair TSMC's 2nm process tech with AMD's CDNA 6 compute architecture, and use HBM4e memory, we can't even begin to estimate what that 1000x claim actually means."
"Calculating AI performance isn't as simple as counting up the FLOPS. It's heavily influenced by network latency, interconnect and memory bandwidth, and the software used to distribute the workloads across clusters. These factors affect LLM inference performance differently than training or video generation. Therefore, greater than 1000x therefore could mean anything AMD wants it to. Having said that, if AMD wants to stay competitive with Nvidia, the MI500-series will need to deliver performance on par with if not better than Nvidia's Rubin Ultra Kyber racks."
AMD previewed the MI500-series AI accelerators and claimed a 1,000x performance uplift over two-year-old MI300X GPUs. A press release clarified the comparison used an eight-GPU MI300X node versus an MI500 rack system with an unspecified GPU count, making the comparison non-apples-to-apples. MI500 technical details are sparse; it is slated for 2027, will pair TSMC 2nm process with AMD's CDNA 6 architecture and use HBM4e memory. AI performance depends on network latency, interconnects, memory bandwidth and software distribution, and varies between inference, training and generation workloads. Competitive parity with Nvidia's Rubin Ultra Kyber racks will be required.
Read at Theregister
Unable to calculate read time
Collection
[
|
...
]