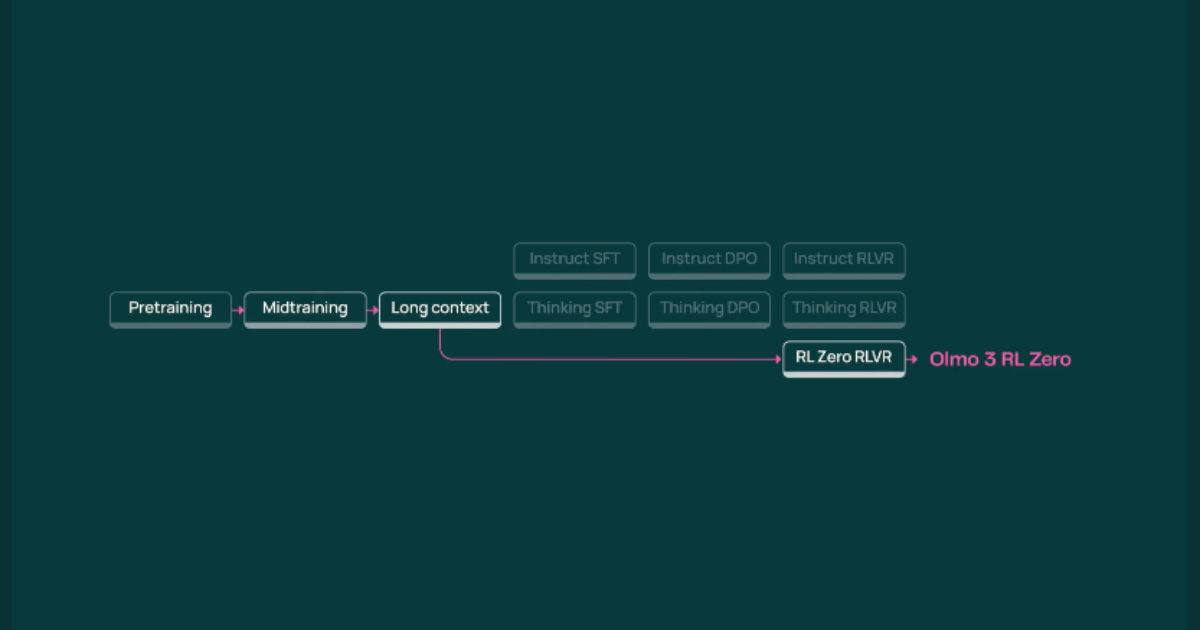
"The Allen Institute for Artificial Intelligence has launched Olmo 3, an open-source language model family that offers researchers and developers comprehensive access to the entire model development process. Unlike earlier releases that provided only final weights, Olmo 3 includes checkpoints, training datasets, and tools for every stage of development, encompassing pretraining and post-training for reasoning, instruction following, and reinforcement learning."
"Language models are often seen as snapshots of a complex development process, but sharing only the final result misses the crucial context needed for modifications and improvements, Ai2 stated in their announcement. Olmo 3 resolves this by offering visibility into the entire model lifecycle, allowing users to inspect reasoning traces, modify datasets, and experiment with post-training techniques like supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR)."
"At the heart of the release is Olmo 3-Think (32B), a reasoning-focused model that allows developers to inspect intermediate reasoning steps and trace outputs back to the training data. For smaller setups, the 7B variants of Olmo 3-Base, 3-Think, and 3-Instruct deliver high performance on coding, math, and multi-turn instruction tasks, all while being runnable on modest hardware. The post-training pathways facilitate different use cases: Instruct is designed for chat and tool use, Think is intended for multi-step reasoning."
The Allen Institute for Artificial Intelligence released Olmo 3, an open-source family of language models that ships checkpoints, training datasets, and tools covering the entire development lifecycle. The release enables inspection of intermediate reasoning traces, dataset modification, and experiments with supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). Olmo 3-Think (32B) focuses on multi-step reasoning with traceability to training data. 7B variants (Base, Think, Instruct) provide strong performance on coding, math, and multi-turn instruction tasks while running on modest hardware. Post-training pathways target chat and tools (Instruct), reasoning (Think), and reinforcement learning research (RL Zero). Models show competitive benchmark performance and long-context capability.
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]