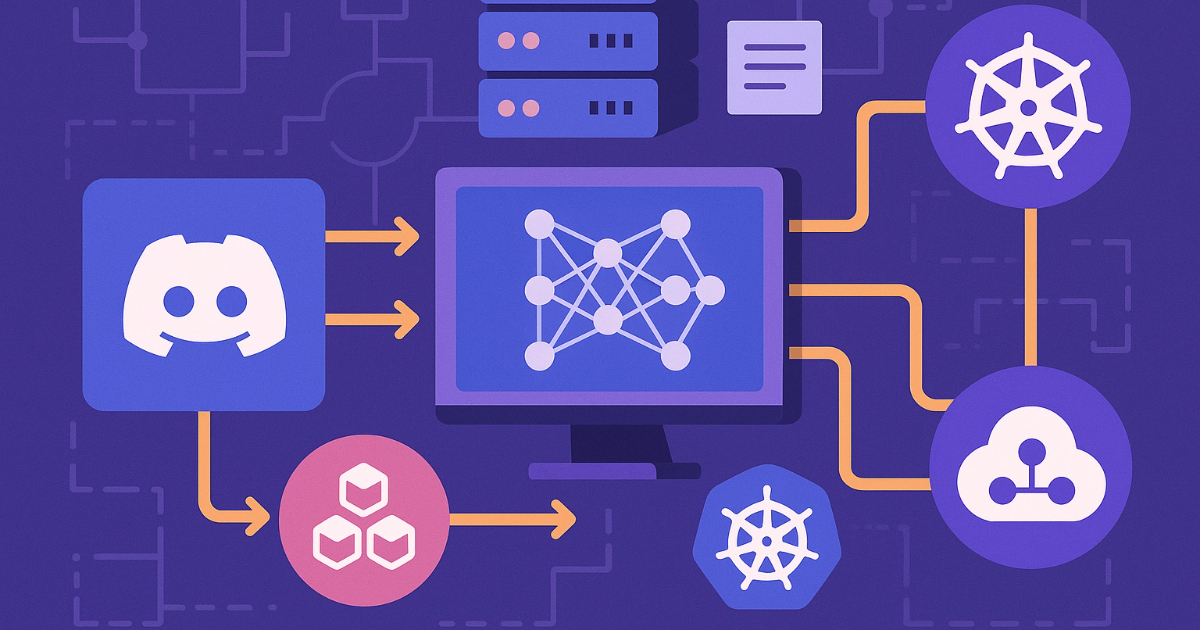
"Discord has detailed how it rebuilt its machine learning platform after hitting the limits of single-GPU training. By standardising on Ray and Kubernetes, introducing a one-command cluster CLI, and automating workflows through Dagster and KubeRay, the company turned distributed training into a routine operation. The changes enabled daily retrains for large models and contributed to a 200% uplift in a key ads ranking metric. Similar engineering reports are emerging from companies such as Uber, Pinterest, and Spotify as bespoke models grow in size and frequency."
"The resulting platform centers on Ray and Kubernetes but is defined by the abstractions on top. Through a CLI, engineers request clusters by specifying high-level parameters, and the tool generates the Kubernetes resources needed to run Ray using vetted templates. This removed the need for teams to understand low-level cluster configuration and ensured that scheduling, security, and resource policies were applied consistently."
Discord rebuilt its ML platform after single-GPU limits by standardising on Ray and Kubernetes, adding a one-command cluster CLI, and automating workflows with Dagster and KubeRay. The platform eliminated ad hoc Ray clusters by generating vetted Kubernetes resources from high-level requests, applying consistent scheduling, security, and resource policies. Dagster now orchestrates pipelines and manages cluster lifecycles, while an X-Ray UI provides visibility into active clusters, logs, and usage. The changes enabled routine distributed training, daily retrains for large models, and measurable performance improvements in ads ranking. Platform standardization reduced configuration drift, unclear ownership, and inconsistent GPU usage.
Read at InfoQ
Unable to calculate read time
Collection
[
|
...
]